
00-前言
Golang 语言简称 go,语言设计的简洁且高效,甚至被认为设计的非常节制,2007 年由 Ken Thompson、Rob Pike、Robert Griesemer 发明,go 语言 2009 年开源,2012 年发布了第一个正式版。
- Ken Thompson 就是发明 Unix 和 C 语言的大神,还设计了 UTF-8编码。

- Rob Pike 也是贝尔实验室的成员,参与了 UTD-8 的设计,协助开发了 Plan9、Inferno、Limbo 等,是 Go 语言项目的总负责人。

- Robert Griesemer 参与了 Java HotSpot 虚拟机开发,负责 Google V8 Javascript 引擎代码生成,对语言设计非常在行。

Go 语言的 logo 是 Rob Pike 的妻子 Renee French 设计的,她是一位才华横溢的插画家。

Go 吸收了众多语言的思想,比如函数式、匿名函数、闭包、携程,推荐使用消息来进行并发编程,内置语法级别的并发特性,特别适用于高性能和分布式领域(系统、存储、网络、游戏、Web、云原生等)。
Go 语言还支持交叉编译,完全支持 UTF-8 编程(字符串使用 UTF-8 编码、源文件格式直接使用 UTF-8 编码保存),在 Go 语言之前 C++ 执行快编译不理想,.NET 和 Java 编译速度很快但是执行效率不高,Go 语言做到了高效编译、高效执行,而且上收难度低,易于开发。
现在一线很多大厂都在使用 go 语言进行系统开发,相对于老牌儿的 C/C++/Java 等编程语言,虽然 go 还很年轻,但随着 go 语言的不断改进和相关生态的完善,使用 go 来构建项目和团队越来越多,Docker、K8S、Etcd、Codis、Consul、Terraform 都是 go 语言开发的,go 1.5 以后实现了自举,去掉了 C 的部分完全用 go 自己来开发。
Go 语言是编译型的而且自带编译器,它的 hello world 版本如下:
package main
import (
"fmt"
)
func main () {
fmt.Println("hello world")
}
将文件保存为 main.go,运行 go run main.go 即可看到 hello world,如果你的系统还没有 go 命令,请立即翻看下一个章节。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/00-helloworld
01-安装和配置
首先需要根据你的系统去这个地址 https://golang.org/dl/ 下载不同的软件包。 
其中 Windows 的默认安装在 c:\go 目录,MacOS 安装在 /usr/local/go。
Linux 的包使用解压命令直接解压到目录 /usr/local/go 里:
wget https://golang.org/dl/go1.15.6.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.15.6.linux-amd64.tar.gz
在 linux 和 macos 里,为了能找到 go 命令,需要把 go 的 bin 目录添加到 PATH 里,在 ~/.bashrc 里加入:
wangbo@wangbo-VirtualBox:~$ echo "export PATH=\$PATH:/usr/local/go/bin" >> ~/.bashrc
wangbo@wangbo-VirtualBox:~$ source ~/.bashrc
在 windows 里修改系统的环境变量 path,加入 /usr/local/go/bin 目录。
安装完后后,打开终端 shell (linux、macos) 或 cmd (windows) 输入 go version 查看到版本说明安装 OK。
wangbo@wangbo-VirtualBox:~$ go version
go version go1.15.6 linux/amd64
使用 go build main.go 编译上一节的 hello world 程序,在当前目录下生成了 main 可执行程序文件,运行后输出 hello world,go 环境安装完成。
wangbo@wangbo-VirtualBox:~/test/go-demo$ go build main.go
wangbo@wangbo-VirtualBox:~/test/go-demo$ ls
main main.go
wangbo@wangbo-VirtualBox:~/test/go-demo$ ./main
hello world
安装完成后的 go 默认设置一些环境变量,可输入 go env 查看:
GO111MODULE=""
GOARCH="amd64"
GOBIN=""
GOCACHE="/home/wangbo/.cache/go-build"
GOENV="/home/wangbo/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOINSECURE=""
GOMODCACHE="/home/wangbo/go/pkg/mod"
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/home/wangbo/go"
GOPRIVATE=""
GOPROXY="https://proxy.golang.org,direct"
GOROOT="/usr/local/go"
GOSUMDB="sum.golang.org"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD=""
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build472416339=/tmp/go-build -gno-record-gcc-switches"
这里为了后面实践代码方便,我们修改 2 环境变量,执行如下命令:
go env -w GO111MODULE=on // 开启模块化包管理系统
go env -w GOPROXY=https://goproxy.cn,direct // 下载包的时候使用国内的镜像地址
它们等效于执行:
export GO111MODULE=on
export GOPROXY=https://goproxy.cn
如果你是 Windows 环境,可以 PowerShell 执行:
C:\> $env:GO111MODULE = "on"
C:\> $env:GOPROXY = "https://goproxy.cn"
Windows 还有一个办法是直接添加系统的环境变量,就像修改环境变量 path 那样,增加 GO111MODULE 和 GOPROXY 两个设定。
对于 go 的 IDE 选择推荐:
Visual Studio Code 下载地址 https://code.visualstudio.com,免费,同时需要安装 Go 和 Code Runner 插件 (ctrl + shift + P 输入 ext install go、ext install coderunner)


JetBrains Goland 下载地址 https://www.jetbrains.com/go 收费,订阅的话每个月大约 20 刀,功能非常强大

本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/01-installation
02-go 语言的程序结构
任何编程语言都有一个基本的结构,然后有变量、表达式、控制、数据、算法、注释来组合完成某个功能,查看上个章节的 hello world 程序,可以看出各个构成部分: 
package 是 go 语言的包,用来组织和分割代码、数据,上面导入的 fmt 包在哪里呢? 移动到 fmt.Println 上鼠标右键或者 F12 使用 go to definition,发现跳转到了一个文件,它的路径是 /usr/local/go/src/fmt/print.go,这是 go 系统自带的包。 
那能不能有自己的包呢? 可以,我们把打印 hello world 的功能移动到自己的包里,新建一个 str 文件夹,添加文件 cn.go,结构如下: 
同理我们在 str 包内再新增一个 en.go 的文件,恢复一个英文问好的函数: 
现在我们在 main.go 文件里来调用我们自己创建包和函数: 
我们把打印的功能分散到了 str 这个包里面,但奇怪的是使用 str 的包的时候,前面多了一个项目的名称,不能直接写成 str 吗,为什么呢? 试想如果系统或者引入的第三方包也有一个叫 str 的名称,那不是就产生了冲突? 所以最好大家把自己的东西都封装在一个模块里,比如我们要的东西都是在 02-dissect-helloworld 这个模块下,那管理起来就比较方便了,那这个模块名在哪里申明的呢? 细心的你可能已经发现了,项目下有个 go.mod 文件,它的内容如下: 
这个 go.mod 文件怎么产生的呢? 运行如下命令即可:
go mod init 02-dissect-helloworld
原来如此,我们运行一下程序,打印出两行结果,因为 fmt.Println 函数会自动在结尾加一个 \n 换行符。 
小结一下:
- 函数 main 是程序的入口,main 函数自己不调用,是系统加载编译后的文件来调用的
- 包 package 用来组织代码和数据,可以是系统的、自己建的、第三方的
- 函数 func main 所在的包名必须是 main,包名称通常是目录名,也可以叫其他名称,但同一个文件夹不同文件的包名必须一样
- 可以用 import 导入别人的包,来扩充自己程序的功能,这样很多东西就不用自己写了,拿来主义
- 打开 GO111MODULE=on 的情况下,go.mod 是申明项目模块化的文件,用来管理程序里所有的包(包括第三方的包)
- 函数是用来实现单个功能的,包里面的函数要给别人用,必须使用大写字母开始
- 系统提供的包在安装 go 的目录下的 src 文件下面,以源代码的方式存在
- package、import、func、main 有特殊的含义,是 go 语言的保留字
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/02-dissect-helloworld
03-变量和类型系统
具有一定功能的程序离不开对数据的操作,以前的章节中,通过给 fmt.Println 函数直接的传递 "hello world" 来实现打印的功能,"hello world" 就是这里的数据,为了更好的表达数据的行为和优化程序的执行,需要给数据加上类型定义。"hello world" 的类型就是字符串,go 语言不仅支持字符,还支持数字、字节、数组、结构、接口等各种派生类型,以后会一一的接触到。
对数据的操作需要把它放到变量里,go 语言可以根据数据的值自动推导变量的类型,比如:
func printHello() {
str := "hello" // 通过 "hello" 推导出 str 是一个字符串类型的数据
fmt.Printf(str)
}
怎么知道 str 就是一个字符串类型呢? 可以通过 fmt 包的格式化打印函数来查看,修改程序代码如下:
func printHello() {
str := "hello"
fmt.Printf("%T\n", str) // %T 用来显示 str 的类型,结果显示 string (\n 表示打印换行符)
fmt.Printf(str)
}
我们也可以明确的去表明一个数据的类型:
func printWorld() {
var str string // 明确的定义 str 是一个字符串类型,具有一个默认的空值
str = "world" // 改变 str 这个数据的值为 "world"
// var str string = "world" // 可以申明变量同时赋初值
fmt.Printf(str)
}
字符串类型是字符的集合,字符类型使用两个单号 '' 表示,在 go 语言中字符类型是 uint8,也叫 byte 字节类型,用于表示 ASCII 码表里的字符,如下代码的作用是打印一个空白字符:
func printSpace() {
var space byte
space = 32
fmt.Printf("%c", space) // 打印 (一个空格,看不见)
fmt.Printf("%T", space) // 打印 uint8
}
因为在 ASCII 码表里空格的数值是 32,%c 表明把 space 变量当做字符来打印,问题是上面的类型打印为什么不是 byte 而是 uint8 呢? 我明明定义了 space 是 byte 字节类型啊? 在 byte 上点右键或者按 F12 使用 go to definition 文件查看:
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
原来 go 语言使用关键字 type 把 uint8 这个 8 位的无符号整型定义成了 byte,byte 就是个昵称(别名),也就说 byte 只是写代码的时候叫 byte,到编译阶段其实都是 uint8 了,为什么要加个别名呢? 因为它的语义性更好,字节类型在程序里太过于常用了,使用 uint8 大家直观上都觉得它只是个数字,但是 byte 有表达字符的意思。byte 真的占用 1 个字节吗? 使用下面的代码验证一下:
fmt.Printf("%d", unsafe.Sizeof(space)) // %d 表示期望打印整数,显示结果是 1
如果用 byte 去申明一个中文可以吗? 如图编辑器提示了错误: 
提示 20013 超出了 byte 的范围,20013 是什么? 因为 ASCII 码表使用 8 位最多表示 256 种字符,可是每个国家都有那么多的文字,于是有了 Unicode 编码集,对世界上大部分的文字进行了整理、编码,让每个符号都有独一无二的编码,让计算机能够处理这些非拉丁字母的文字,这样就不会出错了。由于 Unicode 实现了编码的唯一性和规范,但是在存储设计的并不好,后来就有了 UTF-8 编码的统一规则,对编码和存储都指定了简洁的规范,实现了互联网文字的普及。go 对 UTF-8 支持非常的好。上面文字 中 的UTF-8 编码就是 20013。 
类型 uint8 的最大值是二进制 1111 1111 = 255(2 的 8 次方减 1),它不能表示 20013 这么大的数,直接就被编辑器检测出来了,所以报错。
你可能看到,在前面 type byte = uint8 字节别名定义下还有一个定义:
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
rune 原意是有魔力的符号,int32 占用 4个字节,所以把 byte 换成 rune 就没有问题了。根据 rune 的定义,可以知道它占用了 4 个字节。
func printChinese() {
var ch1 rune = '中'
var ch2 rune = '国'
fmt.Printf("\n%c%c\n", ch1, ch2)
}
除了 uint8,类似的还有 uint16、uint32、uint64,int8、int16、int32、int64 表示不同的位数,u 大头表示无符号整型数字,为了处理小数(浮点数)还有 float32、float64,处理虚数 complex64、complex128 等。
当使用 uint8 和 uint16 有什么区别呢?
第一: 他们表示的范围不同,如果超出了它们的范围,会造成溢出造成非期望的数值。 第二: 他们占用的内存空间不同,运行的时候编译器会为变量开辟内存空间来存放它们的值,位数越大需要的内存空间越多。
func numberOverflow() {
var num1 uint8 = 50 // 最大表是 256
var num2 uint8 = 50 // 最大表是 256
var num3 uint8
num3 = num1 * num2
fmt.Printf("%d", num3) // 期望是 2500,结果显示 196,改为 uint16 则正常
}
因为 50 的二进制是 110010,110010 和 110010 的乘积(按位相乘再相加)是 100111000100 = 2500,但是 num3 只有 8 位,所以截取末尾的 8 位后结果是 11000100 = 196。所以要选择合适的类型,太大了可能造成浪费给内存分配和回收造成压力,太小了可能可能会造成 bug 产生意料之外的结果。
这些只是 go 的简单数据类型,简单类型还有一个 bool,表示真假,经常用到逻辑判断中。
func printBool() {
b := true
fmt.Printf("%T", b) // 打印 bool
}
字符还有一些其他的表示形式,比如 '\x20' 也是空格,\x 后跟一个 16 进制数,字符串也可以用 `` 反斜杠来保留格式,不过这些不用去记忆,遇到了再学习或者查询 go 语言的相关知识。
func printInitalText() {
str := `I hold keep
myself,
\r\n\t\b
can you?
`
fmt.Println()
fmt.Printf(str)
}
这段文本会按照编写的格式打印出来,带有转义的 \r 回车 \n 换行 \t 跳格 \b 回退 也会原样输出。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/03-type-definition
04-函数签名和使用
前面的例子,我们使用了很多函数,为了不让你惊慌,决定先讲一点儿 go 语言函数的基本知识,后面的章节还要深入讲解。
函数在程序设计里翻译为功能为合适,就像数学里的 y=f(x),如果没有函数,所有的代码都要写在 main 里面,不但无法使用现成的功能,还会造成臃肿不可维护(同样的任务不可能写两遍重复的代码),所以函数的作用就是组织代码和实现功能重用。
函数在任务上应该单一,一个函数只做好一件事即可。go 语言的函数由 func 关键字开始申明,完整的函数包含函数名称、参数列表、返回值、函数体。如果一个函数没有参数,也没有返回值,就只剩下函数名和函数体了。
func doNothing() {
// 函数体
}
不过函数也可以匿名,也就没有没有函数名称,或者把函数赋值给一个变量。
// 直接调用一个匿名函数
func anonymous() {
func() {
fmt.Println("i am anonymous function")
}() // 注意这个括号
}
func holdFuncWithVar() {
// 把函数复制给一个变量
f := func(name string) {
fmt.Printf("hey, %s\n", name)
}
// 显示 func(string)
// fmt.Printf("%T", f)
f("zhangsan")
}
下面是一个有参数和返回值的函数,函数的返回结果使用 return 来表示。
// 函数有返回值
func incNumber(in int) int {
return in + 1
}
go 的函数也可以有多个返回值。
// 函数有多个返回值
func swapStr(s1, s2 string) (string, string) {
return s2, s1
}
函数的参数可以有一个不定参数,不过它必须是参数列表最后一个,我们用的 fmt.Println 的参数就是不定参数(F12 去看看)。
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
返回值可以申明一个具体的变量,这样返回的时候就只写 return 就可以了。
// more 是不定参数,result 是返回变量
func sumAllWithInitial(initial int, more ...int) (result int) {
result = initial
// 循环读取 more 参数,以后会学习
for _, num := range more {
result = result + num
}
// 等效于 return result
return
}
go 有很多内置的函数,比如 len、copy、append 等等。
func builtInFunc() {
str := "english中文"
// len 是一个内置函数
// 对于 string 它返回字节
fmt.Println(len(str)) // 返回 13,因为 1 个中文 UTF-8 这里存储占 3 个字节
}

关于函数还有很多重要的知识点,目前暂且知道这么多,第 8 小节再深入学习,下一章学习语言的控制结构。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/04-basic-func
05-条件和循环结构
程序代码很多时候就是对现实的表达,比如买一个东西,要看你有没有带够钱,这种逻辑关系就是判断条件。
//CanBuy 判断钱是否足够
func CanBuy(hasMoney, productPrice int) {
// if 后面不需要括号,if 的执行体无论是否为空 { } 都是必须的
if hasMoney >= productPrice {
fmt.Printf("you can, will %d left", hasMoney-productPrice)
}
}
if 满足的时候执行 if 的函数体,如果不满足需要执行还可以跟一个 else 语句,如果还有判断可以接 else if 语句。
if 天不下雨 {
// 出去吃
} else if 有肉和菜 {
// 将就吃
} else {
// 点外卖
}
注意 go 语言的 if 不需要括号 (),而 if 后面的执行体总是需要括号 {},if 里可以嵌套 if,但是写代码的时候应该放置嵌套过深,if 虽然好用但是会增加代码的复杂度,下面几个函数,你觉得哪个会好一点呢?
//CheckPrice1 判断贵不贵
func CheckPrice1(amount int) {
if amount > 50 {
if amount > 100 {
fmt.Println("太贵了")
} else {
fmt.Println("还行")
}
} else {
fmt.Println("真便宜啊")
}
}
//CheckPrice2 判断贵不贵
func CheckPrice2(amount int) {
if amount > 50 {
if amount > 100 {
fmt.Println("太贵了")
} else {
fmt.Println("还行")
}
return
}
fmt.Println("真便宜啊")
}
//CheckPrice3 判断贵不贵
func CheckPrice3(amount int) {
if amount > 100 {
fmt.Println("太贵了")
} else if amount > 50 {
fmt.Println("还行")
} else {
fmt.Println("真便宜啊")
}
}
//CheckPrice4 判断贵不贵
func CheckPrice4(amount int) {
if amount <= 50 {
fmt.Println("真便宜啊")
return
}
if amount > 50 && amount <= 100 {
fmt.Println("还行")
} else {
fmt.Println("太贵了")
}
}
//CheckPrice5 判断贵不贵
func CheckPrice5(amount int) {
if amount > 100 {
fmt.Println("太贵了")
return
}
if amount > 50 {
fmt.Println("还行")
return
}
fmt.Println("真便宜啊")
}
你可能学过 C 语言的三目运算符,觉得它们看起来都不太好,不过 go 不支持三目运算符,因为三目运算符能写出非常复杂的代码。就目前学习的知识点来看,版本 checkPrice5 相对来讲没有过多的嵌套的层级,使用 if 的时候要特别注意这个代码复杂度的问题。
除了判断,就是循环,for 循环可以指定执行的次数,完整的 for 循环是:
// FullFor 完整的 for 定义
func FullFor() {
sum := 0
// 初始值; 循环条件; 增量/减量
for i := 0; i < 10; i++ {
sum += i
}
fmt.Println(sum)
}
初始值和增减量是可以没有,这时候两边的分号也可以不写了。
// ConditionFor 只有循环条件
func ConditionFor() {
sum := 1
// for ; sum < 10 ; {
for sum < 10 {
sum += sum
}
fmt.Println(sum)
}
如果连循环条件也没有,那就是死循环了,一直出不来,你需要用 ctrl + c 或者 kill 来结束掉进程,在一个中如果出现死循环往往是致命的,可能导致 CPU 超级高,但是程序本身并没有做什么有意义的事情。
// DeadFor 死循环
func DeadFor() {
for true {
// 无限循环
}
for {
// 无限循环
}
}
for 循环的过程,可以使用 continue 来跳过当次循环,使用 break 中断循环。
//BreakContinueFor 跳过和中断
func BreakContinueFor() {
for i := 0; i < 100; i++ {
// 余数是 0 是偶数,跳过
if i%2 == 0 {
continue
}
// 大于 10 就中断循环
if i > 10 {
break
}
fmt.Printf("%d ", i)
}
fmt.Println()
}
for-range 用来迭代字符串、数组、切片等类型,index 是迭代的索引,类似循环变量,ch 是拷贝的迭代值,for-range 有一些要注意的知识点和坑,以后会经常用到它。
// ForRange 安全的迭代循环
func ForRange() {
str := "this is a test"
for index, ch := range str {
// 跳过空格不处理
if ch != 0x20 {
fmt.Printf("%d%c ", index, ch)
}
}
fmt.Println()
}
如果不关心循环的具体值,可以不写 for-range 的第二个循环变量。
// ForRange2 安全的迭代循环
func ForRange2() {
str := "this is a test"
for index := range str {
fmt.Printf("%d ", index)
}
fmt.Println()
}
如果不关心循环的次数,index 却不能不写,但是可以使用 _ 占位符来代替,表示不关心它具体的值。
// ForRange3 安全的迭代循环
func ForRange3() {
str := "this is a test"
for _, ch := range str {
fmt.Printf("%c", ch)
}
fmt.Println()
}
switch-case 用于不同的条件执行不同的动作,每个 case 都是一个分支,挨个比对值,如果匹配就执行对应的分支,后面的分支不再测试,注意 case 分支不需要加 break。
// FullSwitch 挨个顺序匹配
func FullSwitch(rank string) {
switch rank {
case "gold":
fmt.Println("1st")
case "silver", "bronze":
fmt.Println("2nd or 3rd")
default:
// 匹配不到才会执行
fmt.Println("未获奖")
}
}
switch-case 有个特殊的 fallthrough 用法,它会无条件的执行匹配到的下一个case。
// FallThrough 执行匹配到下一个 case 语句(无论它的条件是真是假)
func FallThrough() {
switch {
case true:
fmt.Println("我是匹配到的")
fallthrough
case false:
fmt.Println("虽然我是 false,但我会被打印")
fallthrough
case false:
fmt.Println("虽然我也是 false,但我也会被打印")
// fallthrough
// 如果放开这个 fallthrough,下面的 default 也会被执行
default:
fmt.Println("放开上面的 fallthrough 才能看到我")
}
}
goto 语句可能被认为是洪水猛兽,因为滥用 goto 可能是程序的逻辑变得混乱,go 语言支持 goto 语句,需要一个 label 来配合申明,下面的代码使用 goto 跳出 3 层 for 循环,如果使用 if + break 需要做标记变量层层判断(break 不能中断外层的循环体),使用 goto 简化了代码复杂度。
//JumpOutside 使用 goto 跳出多层循环
func JumpOutside() {
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
for k := 0; k < 10; k++ {
fmt.Println(i, j, k)
if i == 1 && j == 2 && k == 3 {
goto GAMEOVER
}
}
}
}
GAMEOVER:
fmt.Println("game over")
}
select 分支语句是 go 语言非常重要的分支判断语句,在学了通道以后会用的特别多,也是有别于其他语言的一个语法。select 带有多个 case,每个 case 都是一个 IO 操作,select 随机的选择满足条件的执行一个,重点来了,如果没有 case 可以运行,它将发生阻塞,一直等到有一个 case 满足条件位置。所以下面的代码是一个死循环,一直会阻塞,因为它没有 case,永远都不会满足一个。
// DeadSelect 一直阻塞
func DeadSelect() {
select {}
}
由于我们还没有学习关于通道的知识,本节暂时略过 select 语句,它非常重要,在学习通道的时候会详细讲解它的用法。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/05-condition-loop
06-常量和变量引用
使用 var 申明的叫变量,有些数据在运行过程不会被改变或则防止被改变,使用常量更好,常量的意思就是申明赋值后就不会再改变了,如果某个地方不小心改变了它,编译器就会报错。 
常量类型也是可以推导值,下面等价:
const score int = 10
const score = 10
常量对数据的类型有限制,只能是布尔、数字和字符串,数字包含整数、浮点数、虚数。比如
const space byte = 0x20
之前的代码我们使用过 unsafe.Sizeof 计算字节大小,这个函数其实是在编译器就能确定的,它只和变量的类型有关系,和变量指向的缓冲区长度没有关系,比如对于字符串来讲,因为 go 内部用 2 个字段来表示字符串类型,2 个字段各占用 8 个字节,所以对字符串使用 unsafe.Sizeof 返回 16,因为这个大小在编译器就能确定,不会再更改了,所以 unsafe.Sizeof 的结果其实可以直接赋值给 const 常量。学过 C 语言的要特别注意,此 sizeof 不是 C 的那个 sizeof。
// CompileSizedof 编译器确定所以可以给 const 赋值
func CompileSizedof() {
str := "english 中文"
const byteInSize = unsafe.Sizeof(str)
// 不管 str 是什么内容 byteInSize 都是 16
// 字符串在 go 内部用 2 个字段表示(一个地址值和一个长度值,都占用 8 个字节)
fmt.Println(byteInSize)
}
下面的字符串的类型定义:
// https://github.com/golang/go/blob/0e85fd7561de869add933801c531bf25dee9561c/src/reflect/value.go#L1973:6
// StringHeader is the runtime representation of a string.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type StringHeader struct {
Data uintptr
Len int
}
uintptr 是一个地址值,在 64 位它的定义是:
typedef unsigned long long int uint64;
typedef uint64 uintptr;
类型和平台有关系,官方文档里的解释 int 至少是 32 位,也就是在 64 位(AMD64/X86-64)的电脑上,它就是 64 位的,如果你本地运行结果不是 16,请确认一下你的电脑的 cpu 架构以及你的 go 版本是不是过低(在 1.1 以下)。
扯远了,说常量呢。
go 语言里经常把常量用作枚举,可以如下定义:
const (
appple = 0
banana = 1
orange = 2
)
不过这样 0 1 2 给维护增加了负担,go 语言定义了一个特殊的常量叫 iota,编译的时候会被编译器修改,它的作用是在 const 第一行被设置成 0,每增加一行,它的值就会累加一次,就像是 const 的索引。所以下面的定义还是 0 1 2:
const (
appple = iota
banana = iota
orange = iota
)
简写如下:
const (
appple = iota
banana
orange
)
所以当你看到这个奇怪的关键字时不要紧张,每行它就累加 1。
在编译期不能确定的就是变量了,它的值在运行期会被修改,编译器会给它分配一个内存地址和相应的内存空间,这个内存地址在运行的时候是确定的,如果把这个内存地址赋值给另外一个变量,这个变量就是指针变量,表示它是指向那个内存地址。怎么获得一个变量的地址呢? 使用 & 操作符,用 %p 来格式化。
// PrintAddr 打印变量的地址
func PrintAddr() {
score := 10
fmt.Printf("%p\n", &score) // 打印 0xc00001c118
}
持有变量地址的指针变量可以通过 * 操作符读取它地址里存放的值,并且修改它。
// HoldVarAddr 持有变量的内存地址
func HoldVarAddr() {
score := 10
addr := &score
*addr = 20
fmt.Println(score) // 打印 20
}
在都用函数的过程,默认参数是按照值传递的,对于普通的变量类型,传递的参数会被拷贝一份压入堆栈,这种情况下函数体内的代码不会影响到传入的参数本身,因为他们的内存地址并不是同一个位置。所以下面的代码无法修改 score 的值。
// 不能修改入参 score 参数值
// 函数调用的时候参数被拷贝
func cannotUpdateScore(score int) {
fmt.Println(&score) // 0xc00001c138
score++
fmt.Println(score) // 11
}
// IncScoreFailed 调高分数
func IncScoreFailed() {
score := 10
fmt.Println(&score) // 0xc00001c130
cannotUpdateScore(score)
fmt.Println(score) // 10
}
运行可发现上面两个 score 的内存地址是不同的,如果希望 score 参数被修改,就得传入它的内存地址,函数调用的时候这个内存地址值被拷贝,传过去,函数修改了内存地址中存放的值,使得 score 被修改了。
// 可以修改入参 score 参数值
// 函数调用的时候参数被拷贝
func canUpdateScore(ptrScore *int) {
fmt.Println(ptrScore) // 已经是地址了 0xc00001c140
*ptrScore++
fmt.Println(*ptrScore) // 11
}
// IncScoreSuccssed 调高分数
func IncScoreSuccssed() {
score := 10
fmt.Println(&score) // 0xc00001c140
canUpdateScore(&score)
fmt.Println(score) // 11
}
传过去的内存地址都是 0xc00001c140,把这个内存地址的值累加后,反应到了原来指向这个内存地址的 score 变量上,也就是 ptrScore 和 &score 都持有 score 的把柄,可以随意的操纵它。
在 go 语言里面,除了调用 unsafe 包的函数外,不能直接对指针进行运算,修改指针的内存地址值。在上面的代码中,对 ptrScore++ 是不被允许的。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/06-const-var-reference
07-单元测试和重构
在前面的例子中,我们需要依靠在 main 函数中调用包内的函数,根据 fmt.Println 来确定函数是不是按照预期的工作,这非常的不方便,因为函数可能是包内小写的私有函数,它并不需要暴露到外面,而且函数可能压根不需要输出任何东西,它只要把数据处理好就行了,所以得学会怎么测试代码的正确性。
把上个章节的 incUpdateScore 函数复制一下,放到 varpointer 包下面取名 memaddr.go,内容如下:
func incUpdateScore(ptrScore *int) {
*ptrScore += 2
}
同样的目录下新建一个 memaddr_test.go 的文件,注意以 _test 结尾,输入以下内容:
func Test_incUpdateScore(t *testing.T) {
score := 10
expected := 11
incUpdateScore(&score)
if score != expected {
t.Errorf("有问题, 期望 %d, 实际是 %d", expected, score)
}
}
注意函数名称以 Test 开头,参数类型是 *testing.T,在函数名称上出现了一排工具栏,点 run test 后,输出如下:
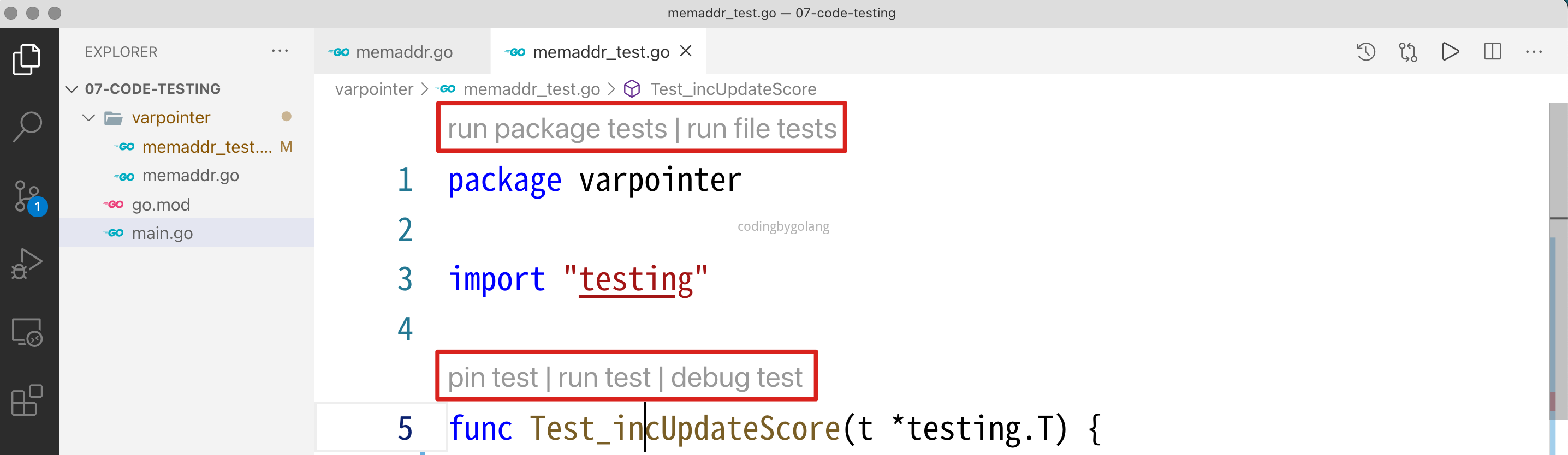
--- FAIL: Test_incUpdateScore (0.00s)
/Users/wangbo/Desktop/go-demo/07-code-testing/varpointer/memaddr_test.go:11: 有问题, 期望 11, 实际是 12
FAIL
FAIL 07-code-testing/varpointer 0.465s
FAIL
测试失败了,期待加上 1,结果加了2,修复代码:
func incUpdateScore(ptrScore *int) {
*ptrScore++
}
现在结果显示:
ok 07-code-testing/varpointer 0.785s
说明函数测试通过了,在终端 shell 使用 go test -v ./... 依然显示测试通过:
07-code-testing[master*] 🍎 go test -v ./...
? 07-code-testing [no test files]
=== RUN Test_incUpdateScore
11
--- PASS: Test_incUpdateScore (0.00s)
PASS
ok 07-code-testing/varpointer 0.341s
小结一下,测试包内的函数步骤:
- 新建一个 xx_test.go 的文件
- 新建函数 Test_funcName,它的参数 t *testing.T
- 编写测试代码
- 使用 go test 命令来运行测试文件
现在我们来对 incUpdateScore 进行重构,我们希望递增的分数是以参数的形式传进去:
func incUpdateScore(ptrScore *int, increment int) {
*ptrScore += increment
}
保存文件后发生 vscode 自动运行了测试,并且报告了测试失败:
# 07-code-testing/varpointer [07-code-testing/varpointer.test]
/Users/wangbo/Desktop/go-demo/07-code-testing/varpointer/memaddr_test.go:8:16: not enough arguments in call to incUpdateScore
have (*int)
want (*int, int)
FAIL 07-code-testing/varpointer [build failed]
FAIL
编译都没有通过,因为我们修改了函数签名,但是还没有修改测试代码,重构测试代码如下:
func Test_incUpdateScore(t *testing.T) {
score := 10
expected := 11
incUpdateScore(&score, 1)
if score != expected {
t.Errorf("有问题, 期望 %d, 实际是 %d", expected, score)
}
}
保存后看到测试通过了,传入正数函数工作正常,我们想测试一下负数的情况,使用 t.Run 来包装 2 个测试场景,继续重构为 2 个子测试代码如下:
func Test_incUpdateScore(t *testing.T) {
checkEqual := func(t *testing.T, expected, got int) {
t.Helper()
if expected != got {
t.Errorf("有问题, 期望 %d, 实际是 %d", expected, got)
}
}
t.Run("should increment score by + number", func(t *testing.T) {
score := 10
incUpdateScore(&score, 1)
checkEqual(t, 11, score)
})
t.Run("should increment score by - number", func(t *testing.T) {
score := 10
incUpdateScore(&score, -1)
checkEqual(t, 9, score)
})
}
再次运行测试也通过了,说明函数 incUpdateScore 具有预期的行为,这个过程我没有没有借助 main 函数和 fmt 包就完成了测试和重构。
07-code-testing[master*] 🍎 go test -v ./...
? 07-code-testing [no test files]
=== RUN Test_incUpdateScore
=== RUN Test_incUpdateScore/should_increment_score_by_+_number
=== RUN Test_incUpdateScore/should_increment_score_by_-_number
--- PASS: Test_incUpdateScore (0.00s)
--- PASS: Test_incUpdateScore/should_increment_score_by_+_number (0.00s)
--- PASS: Test_incUpdateScore/should_increment_score_by_-_number (0.00s)
PASS
ok 07-code-testing/varpointer 0.559s
但是这两个测试场景有一些重复性的代码,有点让人爽对不对,函数就是消除重复代码的好办法,我们再次重构一下。
func Test_incUpdateScore(t *testing.T) {
checkEqual := func(t *testing.T, expected, got int) {
t.Helper()
if expected != got {
t.Errorf("有问题, 期望 %d, 实际是 %d", expected, got)
}
}
t.Run("should increment score by + number", func(t *testing.T) {
score := 10
incUpdateScore(&score, 1)
checkEqual(t, 11, score)
})
t.Run("should increment score by - number", func(t *testing.T) {
score := 10
incUpdateScore(&score, -1)
checkEqual(t, 9, score)
})
}
刚才创建的测试是单元测试,go test 还支持基准测试,自定义入口测试等,以后的章节会经常用到测试,需要掌握它。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/07-code-testing
08-学习复杂数据类型
把有限的相同数据类型的变量集合到一起就叫数组(有些语言的数组元素类型可以不同),组成数组的个体叫元素,元素的顺序编号称为下标,一般下标从 0 开始(有些编程语言从 1 开始),数组有固定的长度,分布在一段连续的内存空间中,因为是连续的,通过下标来访问数组中的元素很高效(计算内存地址偏移很简单)。
下面申明一个整数数组:
var arr [3]int // 申明
var arr [3]int = [3]int{1, 2, 3} // 申明并设置初始值
var := [3]int{1, 2, 3} // 推导
arr := [...]int{1, 2, 3} // 根据初始值来分配
go 的数组还有一个特殊的申明:
// 等效于 [5]int{0, 2, 3, 0, 0}
arr := [5]int{1:2, 2:3} // 数组的大小是5,第 2 个元素的值是 2,第 3 个元素的值是 3,没有指定的就是 int 零值(0)可以
可以使用内置函数 len 获得数组的大小。
func initialSpecial() [5]int {
arr := [5]int{1: 2, 2: 3}
fmt.Println(len(arr)) // 输出 5
fmt.Printf("%T\n", arr) // 输出 [5]int
return arr
}
go 的数组是一个值类型,把一个数组直接传递给函数,将发生数据拷贝,函数内对参数数组的改变不会影响到原数组。
func updateFailed(arr [3]int) {
fmt.Printf("%p\n", &arr) // 0xc000014340
arr[0] = 1
arr[1] = 1
arr[2] = 1
fmt.Println(arr) // [1 1 1]
}
func Test_updateFailed(t *testing.T) {
arr := [3]int{1, 2, 3}
fmt.Printf("%p\n", &arr) // 0xc000014320
updateFailed(arr)
fmt.Println(arr) // [1 2 3]
if !reflect.DeepEqual(arr, [3]int{1, 2, 3}) {
t.Fatal("函数改变了原数组")
}
}
和所有的值类型一样,要修改数组的值,需要传递指针。
func updateSuccessed(ptrArr *[3]int) {
fmt.Printf("%p\n", ptrArr) // 0xc0000cc140
ptrArr[0] = 1
ptrArr[1] = 1
ptrArr[2] = 1
fmt.Println(*ptrArr) // [1 1 1]
}
func Test_updateSuccessed(t *testing.T) {
arr := [3]int{1, 2, 3}
fmt.Printf("%p\n", &arr) // 0xc0000cc140
updateSuccessed(&arr)
fmt.Println(arr) // [1 1 1]
if !reflect.DeepEqual(arr, [3]int{1, 1, 1}) {
t.Fatal("函数改变了原数组")
}
}
当数组特别大的时候,直接传递给函数性能会非常低下。
func printHugeArray1(arr [10000000]int) {
// 啥也不干
}
func printHugeArray2(arr *[10000000]int) {
// 啥也不干
}
func Benchmark_printHugeArray1(b *testing.B) {
arr := [10000000]int{}
for i := 0; i < b.N; i++ {
printHugeArray1(arr)
}
}
// 75 15533465 ns/op 81069791 B/op 1 allocs/op
func Benchmark_printHugeArray2(b *testing.B) {
arr := [10000000]int{}
for i := 0; i < b.N; i++ {
printHugeArray2(&arr)
}
}
// 1000000000 0.298 ns/op 0 B/op 0 allocs/op
这里 testing.B 对对函数进行基准测试,它会运行目标代码 b.N 次,保证测试函数运行足够上的时间。直接传递数组的情况下,需要拷贝一次数组的数据,所以循环了 75 次每次循环的时间是 15533465 纳秒(约等于 0.015 秒,1 秒等于 10 的 9 次方纳秒),而传递数组指针拷贝的是数组指针的值,循环了 1000000000 次每次循环的时间是 0.298 纳秒。
由于数组具有固定的大小,引用的时候不方便,go 把数组作为底层的数据结构作为引用,定了切片类型,也就说切片是对数组一个连续片段的引用,可以是整个数组,也可以是子集。之前我们提到过 StringHeader 字符串的结构,字符串就是一个特殊的数组,而切片的结构定义其实比 StringHeader 多了一个 cap 字段。
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
从这个定义可以看出切片的大小在 64 位 CPU 上是 8 + 8 + 8 = 24 个字节,也就说当函数传递切片参数时,将发生 24 个字节的拷贝。
func sliceSize() {
s1 := []int{} // 构造空的切片
fmt.Println(unsafe.Sizeof(s1)) // 24
}
如上构造一个切片对象和数组的区别就是,不表明数组元素的大小,既然切片是对数组的引用,那么就可以通过数组来构造切片。
func createSliceFromArray() {
arr1 := [5]int{1, 2, 3, 4, 5}
s1 := arr1[:]
fmt.Printf("%T %T\n", arr1, s1) // [5]int []int
}
arr1[:] 引用了完整的数值,还有以下方式:
s3 := arr1[2:3] // 索引从2开始到3
fmt.Println(s3) // [3]
fmt.Println(len(s3), cap(s3)) // 1 3
s4 := arr1[2:3:4]
fmt.Println(s4) // [3]
fmt.Println(len(s4), cap(s4)) // 1 2
函数 len 返回切片当前有多少个元素,cap 表明切片最多能容纳多少个元素。arr1[2:3] 含义是从索引 2 开始到 3 引用了 1 个元素,切片的容量延续到原引用的最大值 5 但不包含2-3-4 => 3;arr1[2:3:4] 表示从索引 2 开始到 3 引用了 1 个元素,切片的容量一直延续到 4 (不包含),所以容量是 2-3 => 2。结论是 slice = slice[low : high : max] ,low 为截取的起始下标, high 为截取的结束下标(不包含 high 元素),max 为切片保留的原数组容量大小(不包含),如果 max 超过原数组的的大小,会发生溢出错误。
s5 := arr1[2:3:5] // ok
fmt.Println(s5)
fmt.Println(len(s5), cap(s5)) // 1 3
// s6 := arr1[2:3:6] // invalid slice index 6 (out of bounds for 5-element array)
// fmt.Println(s6)
可以使用 append 和 copy 内置函数,修改切片对应的底层数组。
s5 = append(s5, 4)
fmt.Println(len(s5), cap(s5)) // 2 3
s5 = append(s5, 5, 6, 7) // 超过了原来的容量,会自动扩容
fmt.Println(s5) // [3 4 5 6 7]
fmt.Println(len(s5), cap(s5)) // 4 7
s7 := []int{2, 3, 4}
fmt.Println(len(s7), cap(s7)) // 3 3
copy(s7, []int{1, 2, 3, 4, 5})
fmt.Println(s7) // [1 2 3] 超出的元素没有,不会自动扩容
fmt.Println(len(s7), cap(s7)) // 3 3
还有三种写法来创建切片。
s8 := []int{4: 5}
fmt.Println(s8) // [0 0 0 0 5]
fmt.Println(len(s8), cap(s8)) // 5 5
const size = 5
const max = 10
s9 := make([]int, size, max)
fmt.Println(s9) // [0 0 0 0 0]
fmt.Println(len(s9), cap(s9)) // 5 10
s10 := new([]int)
*s10 = append(*s10, 1, 2, 3)
fmt.Println(*s10) // [1 2 3]
fmt.Println(len(*s10), cap(*s10)) // 3 4
make 是内置函数,创建根据类型分配内存和初始化返回类型变量,new 分配内存后返回指向的内存地址--指针,下面是它们的函数签名:
func make(t Type, size ...IntegerType) Type
func new(Type) *Type
把切片传递给函数的基准测试数据,依然高效:
func Benchmark_printHugeSlice(b *testing.B) {
arr := [10000000]int{}
for i := 0; i < b.N; i++ {
printHugeSlice(arr[:])
}
}
// 1000000000 0.295 ns/op 0 B/op 0 allocs/op
key-value 也是经常用的数据类型,go 用 map 来表示无序的键值对,就像字典。
func mapOperate() {
myDict := map[string]string{}
myDict["one"] = "1"
myDict["two"] = "2"
myDict["three"] = "3"
fmt.Println(myDict) // map[one:1 three:3 two:2]
fmt.Println(myDict["one"]) // 1
delete(myDict, "one")
str, ok := myDict["one"]
fmt.Println(ok) // false
fmt.Println(str) // 空
}
map 的 key 键必须是唯一的,因为其内部是哈希表实现来高效搜索,请注意 map 是引用类型,使用的时候应该避免 nil,作为函数参数,对它的修改将反应到调用者。
var scores map[string]int // nil
scores := make(map[string]int)
scores["语文"] = 90
scores["数学"] = 88
var scores map[string]int = map[string][int]{"语文": 90, "数学": 88}
scores := map[string][int]{"语文": 90, "数学": 88}
func updateDict(dict map[string]string) {
dict["four"] = "4"
delete(dict, "one")
}
func Test_updateDict(t *testing.T) {
dict := map[string]string{"one": "1", "two": "2", "three": "3"}
updateDict(dict)
fmt.Println(dict) // map[four:4 three:3 two:2]
}
可以使用 len 函数获得 map 的键个数,delete 来删除 map 中的元素,对 map 取值有个特殊的语义:
delete(scores, "数学")
fmt.Println(len(scores))
score := scores["语文"]
score, ok := scores["语文"] // 不存在 ok 为 false
使用 for-range 很方便的遍历 map 的元素,注意不能保证顺序:
for key, value := range myDict {
fmt.Println(key, value)
}
for key := range myDict {
fmt.Println(key, myDict[key])
}
可以使用 map 去表达一个复杂对象,比如对于一本书来说,有作者、名称、出版时间等,但是语义上就不会那么清晰,而且 map 的键必须是相同的类型,对于出版时间,明显使用日期时间数据类型更好,表达这类数据最好的办法是使用 struct 结构体:
func defineBook() {
book := struct {
Name string
Author string
Publish time.Time
}{"算法导论", "大神", time.Now()}
fmt.Printf("%T\n", book) // struct { Name string; Author string; Publish time.Time }
fmt.Println(book)
}
为了更好的表达语义,可使用 type 定一个 Book 类型:
//Book 书
type Book struct {
Name string
Author string
Publish time.Time
}
func useBookStruct() {
book1 := Book{}
fmt.Println(book1)
book2 := Book{
"算法导论", "大神", time.Now(),
}
fmt.Println(book2)
book3 := Book{
Name: "算法导论", Author: "大神", Publish: time.Now(),
}
book3.Name = "计算机发展史"
fmt.Println(book3)
}
struct 结构体是值类型,作为函数参数将发生拷贝。
func changeBookNameFailed(book Book) {
book.Name = "无字天书"
fmt.Printf("%p\n", &book)
fmt.Println(book)
}
func changeBookNameSuccessed(ptrBook *Book) {
ptrBook.Name = "无字天书"
fmt.Printf("%p\n", ptrBook)
fmt.Println(*ptrBook)
}
book := Book{
"算法导论", "大神", time.Now(),
}
fmt.Printf("%p\n", &book)
changeBookNameFailed(book)
fmt.Println(book) // 算法导论
changeBookNameSuccessed(&book)
fmt.Println(book) // 无字天书
}
下面的代码使用 for-range 来遍历数组结构体,请注意 for-range 中迭代循环变量始终是一个,它每次迭代的时候拷贝结构体的值,要获得原结构体的引用需要使用 index 来配合。
//person 人
type person struct {
Name string
Age int
}
func forRangeStruct() {
persons := []person{
{"zhangsan", 20},
{"lisi", 21},
}
for index, item := range persons {
fmt.Printf("%p\n", &item) // 0xc00012a0a0
fmt.Printf("%p\n", &persons[index]) // 0xc000108360, 0xc000108378
fmt.Println(index, item)
}
}
结构体在 go 语言里非常重要,后面还需要继续深入学习它,还有 2 个类型: 接口 interface、chan 通道,先简单的介绍。接口 interface 用来定义一系列共性的方法,比如猫和狗都可以跑和跳,那么就可以用一个接口 Pet 来表示他们的行为:
type Pet interface {
Run()
Jump()
}
在 go 里有一个接口可以表示世间万物,就是空接口,它没有定义任何行为:
// interface{} 世间万物
func emptyInterface() {
var any interface{} = 0 // 给空接口对象初值,否则默认是 nil
fmt.Printf("%T\n", any) // int
any = "test"
fmt.Printf("%T\n", any) // string
any = 3.1415926
fmt.Printf("%T\n", any) // float64
any = []int{1, 2, 3}
fmt.Printf("%T\n", any) // []int
any = struct{}{}
fmt.Printf("%T\n", any) // struct {}
}
这段代码的 struct{} 也表示空结构体,struct {} 在 go 里非常的特殊。
func lookupEmptyStruct() {
a := struct{}{}
b := struct{}{}
if reflect.DeepEqual(a, b) {
fmt.Printf("%p\n", &a) // 0x125a7d0
fmt.Printf("%p\n", &b) // 0x125a7d0
fmt.Println("空结构体都相等")
fmt.Printf("%d\n", unsafe.Sizeof(a)) // 0
fmt.Printf("%d\n", unsafe.Sizeof(b)) // 0
}
}
发现空结构体的地址居然是一样的,而且占用的内存大小是0,很显然是被编译器优化过了,结构体其实可以嵌套,但是空结构体嵌入空结构体,仍然不占用空间。空接口还能表示世间万物,那空结构体有什么用处呢? 下面是一个节省内存的例子,使用 map 来实现 set 结构,set 是指元素不会重复的集合,由于空结构体不占用内存,因此它是一个很好的实现。
func Test_set(t *testing.T) {
// type Set map[string]struct{}{}
set := map[string]struct{}{}
set["one"] = struct{}{}
set["two"] = struct{}{}
set["three"] = struct{}{}
fmt.Println(set["notfound"])
}
在并发编程中,空结构体还经常作为通道 chan 的值。由于目前还没有学习 "面向对象、并发编程" 的知识,所以对 struct、interface、chan 暂时不再深入了,但是记住他们是 go 最重要的部分。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/08-complex-data-type
09-深入学习函数调用
目前已经多次使用到函数了,包括系统的内置函数 len、cap、append、copy、delete、make、new 等,后面会接触到更多的内置函数,比如 panic、recover、close 等等。
函数调用的时候编译器会计算函数需要使用的栈空间,记录调用下一个函数的函数、函数返回后的下一个指令位置、当前函数的栈基址、被调用函数的本地变量,记录的意思就是把它们压入执行栈,被调用的函数指令执行完了后再跳回到原来指令的位置(先进后出),继续执行原来函数的下一条指令,层层调用直到 main 函数执行完毕退出,而且栈空间大小是不断调整的。
首先回到 main 函数,go 语言除了 main 这个特殊的函数外,还有一个 init 函数也比较特殊,如果包内出现了 init 函数,它将首先被调用。
package initial
import "fmt"
func init() {
fmt.Println("init called in initial package")
}
包 initial 下的 init 函数,只要导入这个包,init 函数就会被执行(不用调用包内的其他函数)。
import (
_ "09-inside-func/initial"
)
_ 表示忽略占位符,这个写法就是导入包,但是又不打算调用包内的函数,目的就是让它触发 init 的调用,该函数不能有参数和返回值,也不能被其他函数显示调用,每个包内可以有多个 init 函数,甚至每个源文件都可以有多个 init 函数,但请注意同一个包内的 init 函数执行顺序并不能保证,不同的包的 init 顺序按照导入包的依赖关系(不是导入包的编码顺序) 来执行,所有的 init 函数比 main 函数还先执行。那 init 有什么应用场景呢?
- 初始化变量
- 程序运行前的独立的准备工作
- 实现只调用一次 once 的功能 (init 的机制决定了只会被执行一次,很可靠)
- 配合日志用于调试包的导入顺序等问题
前面的章节示例知道,函数可以赋值给一个变量,也可以是匿名函数直接运行,函数也可以作为一个函数的返回值,也就是返回函数的函数。
func getNameFunc(name string) func() string {
return func() string {
return name
}
}
这个函数返回一个 "没有参数而且返回字符串" 的函数,下面的调用它的代码:
func Test_getNameFunc(t *testing.T) {
f1 := getNameFunc("zhangsan")
f2 := getNameFunc("lisi")
fmt.Println(f1()) // zhangsan
fmt.Println(f2()) // lisi
}
很显然,函数可以作为函数的返回值,也能作为函数的参数传递。
// NameExchangeFunc 变换名称的函数
type NameExchangeFunc func(string) string
func doubleNameFunc(name string) string {
return name + name
}
func upperNameFunc(name string) string {
return strings.ToUpper(name)
}
// func changeName(name string, f func(string) string) string {
func changeName(name string, f NameExchangeFunc) string {
return f(name)
}
为了简化参数的写法,重新定义了 NameExchangeFunc 类型,函数 changeName 第一个参数表示待处理的名称,第二个参数表示处理的策略方案,由调用者来指定,对函数的引用直接使用它的名称。
func Test_changeName(t *testing.T) {
doubleName := changeName("zhangsan", doubleNameFunc)
upperName := changeName("lisi", upperNameFunc)
fmt.Println(doubleName) // zhangsanzhangsan
fmt.Println(upperName) // LISI
}
函数的最后一个参数支持可变参数,它的本质是切片,很多库函数都使用可变参数。
func joinAll(prefix string, strs ...string) string {
str := prefix
// 可变参数的本质是切片
fmt.Printf("%T\n", strs) // []string
for _, s := range strs {
str = fmt.Sprintf("%s-%s", str, s)
}
return str
}
func Test_joinAll(t *testing.T) {
str := joinAll("prefix", "one", "two", "three")
fmt.Println(str) // prefix-one-two-three
}
递归是函数很重要的特性,运行过程中自己调用自己就是递归,递归一定要有结束函数运行的条件,否则函数调用上下文不断的压入栈,会导致栈溢出。
func willDie() {
willDie()
}
// fatal error: stack overflow
依据 N 的阶乘是 N * N-1 可以使用递归写出以下的代码:
func factor(num uint64) (res uint64) {
if num > 1 {
res = num * factor(num-1)
return
}
return 1
}
注意递归退出的条件是被计算的数 > 1,如果 num 等于 1,直接返回 1,比如 6 的计算过程如下:
res = 6 * factor(5) // 压栈
res = 6 * 5 * factor(4) // 压栈
res = 6 * 5 * 4 * factor(3) // 压栈
res = 6 * 5 * 4 * 3 * factor(2) // 压栈
res = 6 * 5 * 4 * 3 * 2 * factor(1) // 压栈
res = 6 * 5 * 4 * 3 * 2 * 1 // 出栈
res = 6 * 5 * 4 * 3 * 2 // 出栈
res = 6 * 5 * 4 * 6 // 出栈
res = 6 * 5 * 24 // 出栈
res = 6 * 120 // 出栈
res = 720 // 返回
可见递归函数的缺点就是函数调用压栈,会一直增加栈的使用空间,如果栈空间被耗尽,就会发生溢出,把函数的条件反过来重构一下代码,更好理解:
func factor2(num uint64) uint64 {
if num == 1 {
return 1
}
return num * factor2(num-1)
}
对于递归的优化,很多语言有尾递归(TCO-Tail Call Optimization),它的原理是函数最后一步操作(注意不一定是代码中的最后一行语句)是调用它本身,这样函数结束以后没有后续操作,不需要保存当前函数的执行环境,永远只有一个调用记录,编译器可以优化,因为没有必要记录调用时的上下文,抹掉栈的当前函数信息直接替换为新的函数,这样栈的空间始终是一定的。
它的编写套路通常是: 比普通的线性递归函数多一个参数,用这个参数来保存上一次调用函数得到的结果,修改上面的阶乘:
func tailFactor(num, current uint64) uint64 {
if num == 1 {
return current
}
return tailFactor(num-1, num*current)
}
它计算 6 的过程如下:
tailFactor(5,6)
tailFactor(4,30)
tailFactor(3,120)
tailFactor(2,360)
tailFactor(1,720) // 返回
不过对 factor2(10) 和 tailFactor(9,10) 进行基准测试,发现它们的性能差别好像并不大:
// factor2(10)
52402336 23.0 ns/op 0 B/op 0 allocs/op
// tailFactor(9,10)
54346518 22.0 ns/op 0 B/op 0 allocs/op
看起来 go 的编译器并没有对尾递归进行优化,要确定的话需要把这两个函数单独写成文件,反编译出汇编代码看看他们是否有区别:
// factor2
"".factor STEXT size=108 args=0x10 locals=0x18
0x0000 00000 (factor.go:3) TEXT "".factor2(SB), ABIInternal, $24-16
0x0000 00000 (factor.go:3) MOVQ (TLS), CX
0x0009 00009 (factor.go:3) CMPQ SP, 16(CX)
0x000d 00013 (factor.go:3) PCDATA $0, $-2
0x000d 00013 (factor.go:3) JLS 101
0x000f 00015 (factor.go:3) PCDATA $0, $-1
0x000f 00015 (factor.go:3) SUBQ $24, SP
0x0013 00019 (factor.go:3) MOVQ BP, 16(SP)
0x0018 00024 (factor.go:3) LEAQ 16(SP), BP
0x001d 00029 (factor.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d 00029 (factor.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d 00029 (factor.go:4) MOVQ "".num+32(SP), AX
0x0022 00034 (factor.go:4) CMPQ AX, $1
0x0026 00038 (factor.go:4) JNE 59
0x0028 00040 (factor.go:5) MOVQ $1, "".~r1+40(SP)
0x0031 00049 (factor.go:5) MOVQ 16(SP), BP
0x0036 00054 (factor.go:5) ADDQ $24, SP
0x003a 00058 (factor.go:5) RET
0x003b 00059 (factor.go:8) LEAQ -1(AX), CX
0x003f 00063 (factor.go:8) MOVQ CX, (SP)
0x0043 00067 (factor.go:8) PCDATA $1, $0
0x0043 00067 (factor.go:8) CALL "".factor(SB)
0x0048 00072 (factor.go:8) MOVQ 8(SP), AX
0x004d 00077 (factor.go:8) MOVQ "".num+32(SP), CX
0x0052 00082 (factor.go:8) IMULQ AX, CX
0x0056 00086 (factor.go:8) MOVQ CX, "".~r1+40(SP)
0x005b 00091 (factor.go:8) MOVQ 16(SP), BP
0x0060 00096 (factor.go:8) ADDQ $24, SP
0x0064 00100 (factor.go:8) RET
0x0065 00101 (factor.go:8) NOP
0x0065 00101 (factor.go:3) PCDATA $1, $-1
0x0065 00101 (factor.go:3) PCDATA $0, $-2
0x0065 00101 (factor.go:3) CALL runtime.morestack_noctxt(SB)
0x006a 00106 (factor.go:3) PCDATA $0, $-1
0x006a 00106 (factor.go:3) JMP 0
// tailFactor
"".tailFactor STEXT size=114 args=0x18 locals=0x20
0x0000 00000 (tailfactor.go:3) TEXT "".tailFactor(SB), ABIInternal, $32-24
0x0000 00000 (tailfactor.go:3) MOVQ (TLS), CX
0x0009 00009 (tailfactor.go:3) CMPQ SP, 16(CX)
0x000d 00013 (tailfactor.go:3) PCDATA $0, $-2
0x000d 00013 (tailfactor.go:3) JLS 107
0x000f 00015 (tailfactor.go:3) PCDATA $0, $-1
0x000f 00015 (tailfactor.go:3) SUBQ $32, SP
0x0013 00019 (tailfactor.go:3) MOVQ BP, 24(SP)
0x0018 00024 (tailfactor.go:3) LEAQ 24(SP), BP
0x001d 00029 (tailfactor.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d 00029 (tailfactor.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x001d 00029 (tailfactor.go:4) MOVQ "".num+40(SP), AX
0x0022 00034 (tailfactor.go:4) CMPQ AX, $1
0x0026 00038 (tailfactor.go:4) JNE 60
0x0028 00040 (tailfactor.go:5) MOVQ "".current+48(SP), AX
0x002d 00045 (tailfactor.go:5) MOVQ AX, "".~r2+56(SP)
0x0032 00050 (tailfactor.go:5) MOVQ 24(SP), BP
0x0037 00055 (tailfactor.go:5) ADDQ $32, SP
0x003b 00059 (tailfactor.go:5) RET
0x003c 00060 (tailfactor.go:8) LEAQ -1(AX), CX
0x0040 00064 (tailfactor.go:8) MOVQ CX, (SP)
0x0044 00068 (tailfactor.go:8) MOVQ "".current+48(SP), CX
0x0049 00073 (tailfactor.go:8) IMULQ CX, AX
0x004d 00077 (tailfactor.go:8) MOVQ AX, 8(SP)
0x0052 00082 (tailfactor.go:8) PCDATA $1, $0
0x0052 00082 (tailfactor.go:8) CALL "".tailFactor(SB)
0x0057 00087 (tailfactor.go:8) MOVQ 16(SP), AX
0x005c 00092 (tailfactor.go:8) MOVQ AX, "".~r2+56(SP)
0x0061 00097 (tailfactor.go:8) MOVQ 24(SP), BP
0x0066 00102 (tailfactor.go:8) ADDQ $32, SP
0x006a 00106 (tailfactor.go:8) RET
0x006b 00107 (tailfactor.go:8) NOP
0x006b 00107 (tailfactor.go:3) PCDATA $1, $-1
0x006b 00107 (tailfactor.go:3) PCDATA $0, $-2
0x006b 00107 (tailfactor.go:3) CALL runtime.morestack_noctxt(SB)
0x0070 00112 (tailfactor.go:3) PCDATA $0, $-1
0x0070 00112 (tailfactor.go:3) JMP 0
忽略开头和尾部检查栈扩容的代码,两者的核心代码没有区别区别,关于 go 汇编的知识请跳到 29 节查看,如果加大参数会发现 2 个版本都会栈溢出(事实上大部分语言都不支持尾递归,支持的语言(编译器)有 gcc/clang、erlang、lua、scheme、haskell 等):
// factor2(100000000)
// tailFactor(100000000-1, 100000000)
runtime: goroutine stack exceeds 1000000000-byte limit
runtime: sp=0xc0200f0398 stack=[0xc0200f0000, 0xc0400f0000]
fatal error: stack overflow
很多时候在函数返回之前,都需要清理释放资源,比如我们打开文件处理完之后应该关闭它。
func readfile() string {
file, _ := os.Open("/tmp/command.txt") // 示例忽略错误
buf := make([]byte, 10)
size, _ := file.Read(buf)
str := string(buf[0:size])
fmt.Println(str)
if str == "start" {
file.Close()
return "execute service start"
} else if str == "stop" {
file.Close()
return "execute service stop"
}
file.Close()
return "unknow"
}
想提前返回的时候我们需要关闭这个文件流,不但写起来繁琐,很可能在 return 的时候忘了调用 close 方法,造成内存泄露,go 语言使用 defer 语句来处理这类问题,defer 关键字后面跟一个函数调用,它在 return 后但在函数结束前被调用,多个 defer 反序调用。上面的函数可以修改成:
func readfile2() string {
file, _ := os.Open("/tmp/command.txt")
defer file.Close()
buf := make([]byte, 10)
size, _ := file.Read(buf)
str := string(buf[0:size])
fmt.Println(str)
if str == "start" {
return "execute service start"
} else if str == "stop" {
return "execute service stop"
}
return "unknow"
}
不过 defer 有很多坑。首先在 return 之后函数结束之前调用啥意思? 因为 return 是一个复合语句不是原子操作,先赋值,再跳转,下面的例子说明这个情况:
var globalFlag int = 0
func flagFunc() int {
defer func() {
globalFlag = 1
}()
fmt.Printf("callAfterReturn-flag = %d\n", globalFlag) // 0
return globalFlag
}
func callAfterReturn() {
localFlag := flagFunc()
fmt.Printf("callAfterReturn-localFlag = %d\n", localFlag) // 0
fmt.Printf("callAfterReturn-globalFlag = %d\n", globalFlag) // 1
}
localFlag 的结果是 0,说明函数 return 的结果不是 defer 语句修改过的,但 globalFlag 最后是 1,说明的确被 defer 修改了,要确认需要反汇编代码,事实上 defer 是插入在结果赋值和返回之间。
rval = xxx // 返回值赋值给rval
defer_func // 执行defer函数
ret // 函数返回
defer 立刻对表达式求值,对参数进行拷贝,而且 defer 语句只有执行过才会被调用。
func readName(name string) {
fmt.Println("changeName " + name) // changeName zhangsan
}
func passName() {
name := "zhangsan"
defer readName(name) // 拷贝 name
name = "lisi"
fmt.Println("passName " + name) // passName lisi
}
当然如果 defer 参数拷贝的是变量的内存地址,影响就不一样了。
func readNumberRef(ptrNumber *int) {
fmt.Printf("readNumberRef %d\n", *ptrNumber) // readNumberRef 1
}
func passNumberRef() {
number := 0
defer readNumberRef(&number) // 拷贝 number 的地址
number = 1
fmt.Printf("passNumberRef %d\n", number) // passNumberRef 1
}
下面的函数 defer 后的函数不会被执行,因为 defer 本身并没有被执行过。
func wontRun() {
if false {
defer fmt.Println("should not see me") // 不会执行
}
fmt.Println("see me")
}
猜一猜下面的函数打印什么结果?
func printBook(b *book) {
fmt.Println(*b)
}
func walkBooks() {
books := []book{
{Name: "计算机"}, {Name: "电脑"},
}
for _, b := range books {
defer printBook(&b)
}
}
defer 反序执行对吧,应该会打印
{电脑}
{计算机}
实际情况是只会打印 2 个电脑,原因是 for-range 的循环变量 b 始终是一个内存地址,它每次拷贝循环的值,defer 的 printBook 的函数每次调用都传递的是这个 b 的内存地址,修改如下:
for index := range books {
defer printBook(&books[index])
}
下面的代码打印了什么?
func loopForDelay() {
for i := 0; i < 10; i++ {
defer func() {
fmt.Println(i) // 10
}()
}
}
全部打印 10,因为循环结束后 i = 10,defer 的打印语句封闭了外部 i 变量(闭包),修改为参数拷贝的形式就没问题了:
defer func(number int) {
fmt.Println(number) // 9 8 7 6 5 4 3 2 1 0
}(i)
函数的值传递和引用传递,前面的章节已经多次遇到过了,不再详述。
go 语言里一类特殊的函数叫方法,依附于一个 struct 实例上,go 中 struct 其实具有和其他语言 class 一样的地位,在面向对象的章节将详细的介绍方法。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/09-inside-func
10-错误处理机制
编写代码的时候错误大多数是编译错误(语法、类型、格式)等,但是很多错误是运行期才发生的,比如读取文件的时候文件不存在、或者访问切片的时候超过了切片最大的容量,又或者对 nil 的对象进行了操作。
回顾一下前面 defer 章节打开文件的代码:
func read() {
file, err := os.Open("/tmp/test")
if err != nil {
fmt.Printf("%s\n", err)
}
file.Close()
}
os.Open 函数返回了两个值,一个文件对象,一个错误对象,F12 看看它的函数签名:
// Open opens the named file for reading. If successful, methods on
// the returned file can be used for reading; the associated file
// descriptor has mode O_RDONLY.
// If there is an error, it will be of type *PathError.
func Open(name string) (*File, error) {
return OpenFile(name, O_RDONLY, 0)
}
go 语言通常以最后一个参数来表示调用的错误信息,这种错误是编码的时候预知的。如上,如果文件能被顺利的打开,则返回的第二个值 error 对象是 nil,否则是一个 PathError 对象:
// PathError records an error and the operation and file path that caused it.
type PathError struct {
Op string
Path string
Err error
}
PathError 是一个包含三个字段的结构体,Op 表示操作类型、Path 表示文件路径,最后一个 Err 是 error 对象,继续看 F12 看 error 的申明:
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}
是一个接口对象,前面提到过 go 里面表示世间万物的是 interface{} 空接口,error 不是空接口,它只有一个行为 Error() 函数,就是报告一行错误信息。这个库函数告诉我们,在能预估错误的情况,可以包装一个 error 对象返回给调用者,由调用者决定下一步的行为:
func exchangeCommand(cmd string) (string, error) {
if len(cmd) == 0 {
return "", errors.New("cmd should provide")
}
return fmt.Sprintf("service %s", cmd), nil
}
使用 errors.New 函数可以构造一个 error 对象出来,不过这个对象用字符串表示结果,调用者很难去判断错误类型,所以更常见的做法是把错误的信息使用 var 定义错误并暴露到保外,重构一下代码:
//ErrCmdMissing 命令缺失
var ErrCmdMissing = errors.New("cmd should provide")
func exchangeCommand2(cmd string) (string, error) {
if len(cmd) == 0 {
return "", ErrCmdMissing
}
return fmt.Sprintf("service %s", cmd), nil
}
现在调用者可以使用包内的 ErrCmdMissing 来做与判断了,不用纠结于具体的字符串内容是什么。
对于有些严重的错误如果想直接停止程序运行,可以调用内置函数 panic 可以终止,以空字符串为参数来调用下面的函数,程序会终止退出。
func exchangeCommand3(cmd string) string {
if len(cmd) == 0 {
panic(ErrCmdMissing)
}
return fmt.Sprintf("service %s", cmd)
}
运行后提示错误,panic: cmd should provide,随机程序终止。问题是在程序退出之前,往往需要做一些清理操作,或者记录一些日志,甚至是想让代码继续运行,有没有挽救的方法呢? 有,recover 函数可以捕获错误,但是它必须工作在 defer 中。
func exchangeCommand4(cmd string) string {
defer func() {
if err := recover(); err != nil {
if err == ErrCmdMissing {
// 该错误不太重要,记录一下不管它
fmt.Println(err)
} else {
// 其他的错误就致命了
panic(err)
}
}
}()
if len(cmd) == 0 {
panic(ErrCmdMissing)
}
if cmd == "gameover" {
panic(ErrGameOver)
}
return fmt.Sprintf("service %s", cmd)
}
在 recover 中还能继续使用 panic 终止执行,但是 panic 的作用域是函数级别,跨协程是不会影响的,关于协程的知识将在并发的章节学习。
如果错误只能可能是一种,那么 err 的返回值其实可以简单的是一个 bool 类型,比如前面的章节当从 map 结构查询字典的时候:
// val, ok := dict["one"]
if val, ok := dict["one"]; ok {
// 找到了 one 放心返回
return val
}
函数的最后一个参数 error 的范式是 go 语言的特色,也有很多人觉得它设计的太简陋了,因为 error 接口只包含了一段字符串的错误信息,为此常常需要自定义 error 类型,或者把 error 类型嵌套到自己的结构体中,不过如果你遇到 error 不想处理的情况,可以直接把 error 当作本函数的错误返回给上一层调用者,这就是 error 的链式传递。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/10-error-handler
11-详解结构体的应用
go 语言放弃了其他语言的 class 的概念,但是 struct 结构体有同等的地位,可以为结构体定义方法集,前面章节提到的 StringHeader 和 SliceHeader 都是结构体,为结构体添加方法的语法如下:
func (instance Instance) methodName(args...) returnType {
//
}
func (instance *Instance) methodName(args...) returnType {
//
}
上面两个都可以为结构体添加方法,第一种定义方法无法改变 instance 内部的属性,因为它调用的时候值传递它复制的是结构体对象,想要修改结构体实例的属性,需要使用第二种指针定义的方法。
type cat struct {
name string
color string
age int
}
上面定义了一个猫的结构体,小写的 cat 表明不想把它暴露到包外面,给他定义一个年龄增长的方法如下:
func (c cat) grow1() {
fmt.Printf("%p\n", &c) // 0xc000092390
c.age++
}
func (c *cat) grow2() {
fmt.Printf("%p\n", c) // 0xc000092360
c.age++
}
在 grow1 方法中,c cat是调用者的拷贝,而 grow2 中 c *cat 指向调用者的内存地址,所以第一种方法修改的 age 字段无法反应到调用者本身上,一般没有特殊情况,都会使用第二种定义方法,毕竟它的拷贝大小只是一个内存地址。下面的是测试打印的结果:
func Test_cat(t *testing.T) {
myCat := cat{"虎斑猫", "黑黄", 1}
fmt.Printf("%p\n", &myCat) // 0xc000092360
myCat.run()
myCat.jump()
myCat.grow1()
fmt.Println(myCat) // {虎斑猫 黑黄 1}
ptrMyCat := &myCat
ptrMyCat.run()
ptrMyCat.jump()
ptrMyCat.grow2()
fmt.Println(*ptrMyCat) // {虎斑猫 黑黄 2}
}
通过为结构体添加方法集,结构体的所有实例都具备了同样的行为,在设计上完成了抽象和复用。结构体没有继承,但是可以嵌套,假设猫和人都需要一个家庭住址信息,如果直接申明就会有重复:
type cat struct {
color string
address string
phone string
}
type person struct {
sex string
address string
phone string
}
这里 address 和 phone 都是重复信息,可以提取出来一个单独的结构,再嵌入到 cat 和 person 中。
type addr struct {
address string
phone string
}
type cat struct {
color string
addr // 匿名字段
}
type person struct {
sex string
addr // 匿名字段
}
测试代码如下:
func Test_cat(t *testing.T) {
where := addr{address: "东大街", phone: "123"}
c := cat{color: "黑红", addr: where}
fmt.Println(c)
}
func Test_dog(t *testing.T) {
p := person{sex: "女", addr: addr{address: "南大街", phone: "321"}}
fmt.Println(p)
}
如果把 struct 赋值给一个 interface{},如何转换回来呢? 可以使用断言,其实不仅仅是 struct,go 里面 int、string 等基础类型都可以使用断言,因为 interface{} 就像其他语言的 object 一样。
func Test_person(t *testing.T) {
var what interface{}
what = &person{"zhangsan", 20}
if p, ok := what.(*person); ok {
p.eat()
}
}
断言的语法比较特殊 val, ok := target.(type) 意为尝试转换 target 到 type 类型,如果转换成功 ok 为真,val 就是转换后的类型了。断言适合于预知的目标类型,如果编码的时候面对 interface{} 有多种类型的情况或者无法预知类型的情况下,可以使用反射来获得更多的信息:
func Test_person(t *testing.T) {
var what interface{}
what = person{"zhangsan", 20}
// fmt.Println(reflect.TypeOf(what))
// fmt.Println(reflect.ValueOf(what))
val := reflect.TypeOf(what)
switch val.Kind() {
case reflect.Struct:
for i := 0; i < val.NumField(); i++ {
field := reflect.ValueOf(val.Field(i))
fmt.Println(field)
}
default:
fmt.Println("not struct")
}
}
下面介绍 go 的结构体的 tag 用法,用的非常的多,试想如果要把一张数据表的字段映射到结构体上怎么做? go 的方案是用 tag 标签绑定,它常用语 json、xml、bson 等转换的场景。下面的代码把结构体 dump 成 json 字符串:
type record struct {
Name string
Age int
Score float32
}
func Test_record(t *testing.T) {
rec := record{"zhangsan", 20, 98.5}
buf, err := json.Marshal(rec)
if err != nil {
t.Fatal(err)
}
fmt.Println(string(buf)) // {"Name":"zhangsan","Age":20,"Score":98.5}
}
string(buf)是把字节强转为字符串,如果想定义字段的名称可以加上 tag 字段定义,修改 record 结构体如下:
type record struct {
Name string `json:"nickname"` // 字段重命名
Age int `json:"age"`
Score float32 `json:"score"`
}
再次运行测试函数,输出结果如下:
{"nickname":"zhangsan","age":20,"score":98.5}
类似的可以使用 Unmarshal 方法,从 json 字符串中创建出结构体对象。
func Test_recordLoad(t *testing.T) {
rec := record{}
// str := `{"nickname":"zhangsan","age":20,"score":98.5}`
str := `{
"nickname":"zhangsan",
"age":20,
"score":98.5
}`
if err := json.Unmarshal([]byte(str), &rec); err != nil {
t.Fatal(err)
}
fmt.Println(rec) // {zhangsan 20 98.5}
}
[]byte(str)是把字符串强转为字节,如果需要支持 xml 添加 tag 即可,使用 encoding/xml 包可以完成转换,请你去试一试。
func Test_xmlDump(t *testing.T) {
rec := record{"zhangsan", 20, 98.5}
buf, _ := xml.Marshal(rec)
fmt.Println(string(buf)) // <record nickname="zhangsan" age="20" score="98.5"></record>
newRec := record{}
_ = xml.Unmarshal([]byte(buf), &newRec)
if reflect.DeepEqual(rec, newRec) {
fmt.Println("dump and load ok")
}
}
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/11-inside-struct-method
12-面向接口和鸭子模型
接口用于定义对象的一系列行为,表明对象具备某种能力,但是并不规定对象如何实现,空接口 interface{} 没有定义任何行为,所以 go 里面只要是个东西都实现了空接口,难怪 interface{} 可以表示世间万物,要规范接口的行为只需添加方法签名就可以,比如定义一个能 walk 也能 swim 的东西,这个东西可能是个鸭子,也可能是个人。
// Movable 能移动
type Movable interface {
Walk(distance int) int // 走了多久
Swim(distance int) int // 游了多久
}
go 里面实现一个接口不进行语法约束,只要隐形具有 Walk 和 Swim 两个函数的签名就已经实现了 Movable 接口,这样的结构体对象就可以赋值给 Movable 接口对象。
//Duck 鸭子
type Duck struct {
Category string
Name string
WalkSpeed int
SwimSpeed int
}
//Person 人
type Person struct {
Name string
Age int
WalkSpeed int
SwimSpeed int
}
为 Duck 和 Person 都实现 Walk 和 Swim 方法,就可以把它们交给 Movable 对象了。
func hurryUp(moveable move.Movable, distance int) int {
return moveable.Walk(distance/2) +
moveable.Swim(distance/2)
}
func main() {
d := &duck.Duck{Name: "kity", WalkSpeed: 10, SwimSpeed:20}
p := &person.Person{Name: "zhangsan", WalkSpeed: 20, SwimSpeed: 10}
hurryUp(d, 2000)
hurryUp(p, 2000)
d.Egg()
p.Fly()
}
函数 hurryUp 的参数只要求实现了 Movable 接口的对象即可,对象的其他行为它不关心,它不管对象是不是可以下蛋,也不关心对象是否可以飞行,只关心对象能不能 Walk 和 Swim (Ducking Type),不关心它们是什么类型的对象,这就是面向接口编程的鸭子模型。鸭子模型是一种多态的表现,避免写一些大量的重复性的代码。
常用的 error 就是一个接口,它只有一个 Error 方法,Stringer 也可以是常用的接口,它定义了 string 方法,表示对象可以显示成字符串。
type Stringer interface {
String() string
}
比如还有 io.Reader、io.Writer、io.Closer 接口:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
type Closer interface {
Close() error
}
类似结构体一样,接口以可以嵌套,把 io.Reader、io.Writer、io.Closer 接口嵌套结果就是 io.ReadWriteCloser 接口了。
type ReadWriteCloser interface {
Reader
Writer
Closer
}
读取数据可能从文件里读,从标准输入读,从网络套接字里读,但是它们都具备 io.Reader 的行为,所以设计一个函数 readFrom(file *File) 没有 readForm(reader io.Reader) 更通用,后者抽象的更好。
下面的例子用于理解 go 库里面经常出现的 New 函数,它的行为类似设计模式的工厂函数。如果要实现一个负载均衡器算法,从一堆服务器中选择一个节点出来? 有很多方案:
- 默认选择一个
- 随机选择一个
- 轮询选择一个
- 压力最小那个
这就是一个典型的鸭子模型,目的只是选选一个服务器出来,所以可以抽象出一下接口:
type Selector interface {
Select() string
}
默认和随机的选择器实现:
func (b *DefaultBalancer) Select() string {
// 算法略
return "host1:port1"
}
func (b *RandomBalancer) Select() string {
// 算法略
return "host2:port2"
}
暴露一个工厂函数来创建负载均衡器对象,命名常常是 New 或者 NewAbc 等形式:
//New 创建负载均衡器
func New(strategy string) Selector {
switch strategy {
case "random":
return new(RandomBalancer)
default:
return new(DefaultBalancer)
}
}
//NewDefaultBalancer 默认
func NewDefaultBalancer() Selector {
return new(DefaultBalancer)
}
//NewRandomBalancer 随机
func NewRandomBalancer() Selector {
return new(RandomBalancer)
}
调用的方法如下:
func Test_create(t *testing.T) {
selector := New("")
fmt.Println(selector.Select()) // host1:port1
selector = New("random")
fmt.Println(selector.Select()) // host2:port2
}
如果要实现其他的负载均衡算法,改动的代码量很少,大部分都是新增,希望这两个例子能帮你理解接口的作用和 Ducking Type,OOP 面向对象中有很多晦涩的表达,能从你的业务中抽象出接口至关重要,更多的知识细节可以慢慢学习。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/12-interface-ducking-type
13-断言转换和类型反射
前面已经接触过断言了,它的写法有两种形式:
t := i.(T) // 1
t, ok := i.(T) // 2
以上是希望把 i 转换成 T 类型的对象,第一种写法如果转换失败,会触发系统的 panic,导致程序退出;第二种写法如果断言失败,ok 被设置成 false,而 t 被设置成零值。
特殊情况是如果 i 是 nil 也会断言失败,哪怕是转成 interface{} 也不行。
var i interface{} // 默认是 nil 值
_ = i.(interface{}) // panic
_ = i.(string) // panic: interface conversion: interface {} is nil, not string
如果能知道所有预知的类型就不需要断言了,处理起来也会更叫高效、可靠,如何得到类型呢?
func caseType(what interface{}) {
switch what.(type) {
case int:
what = what.(int) + 1
fmt.Printf("number %d\n", what)
case string:
fmt.Printf("string %s\n", what.(string)+" suffix")
case nil:
fmt.Println("you are nothing")
}
}
使用 i.(type) 获取了 i 的类型,这个语法结构叫 type-switch 断言,也就是 i.(type) 只能用在 switch 中,要直接获取类型也只能使用反射来实现,下面的代码实现和上面 type-switch 相同的功能。
func detectType(what interface{}) {
val := reflect.ValueOf(what)
t := val.Type() // Type 是接口对象
fmt.Printf("%T\n", t) // *reflect.rtype
//fmt.Println(t.Name()) // 类型名称
if val.Kind() == reflect.Int {
number := val.Int() + 1
fmt.Printf("number %d\n", number) // number 11
} else if val.Kind() == reflect.String {
fmt.Printf("string %s\n", val.String()+" suffix") // string test suffix
}
}
reflect.ValueOf(what) 获取对象的运行时信息,val.Type 获取对象的类型描述信息(类型、字段、名称、大小、对齐等),它是一个 Type 接口对象 type Type interface {...},val.Kind() 获取反射的数据类型,它其实是 type Kind uint {...} 的定义,这些类型在 go 源文件 src/reflect/type.go 中定义,包括 Bool、Int、Uint、Float、Complex、Array、Chan、Func、Interface、Map、Ptr、Slice、String、Struct、UnsafePointer,通过对每一种类型的特殊处理,就能完全的动态的去处理一个对象。
什么是特殊处理,以指针对象为例,如果 what 是一个指针对象,那么 reflect.ValueOf(what) 的结果是 reflect.Ptr,要获取它指向的对象需要继续调用 val.Elem() 函数,可以提取出这样一个函数
func getReflectValue(x interface{}) reflect.Value {
val := reflect.ValueOf(x)
// Uintptr
// UnsafePointer
if val.Kind() == reflect.Ptr {
val = val.Elem()
}
return val
}
对于 int、string、float 等简单的值可以直接获取,但是对于 reflect.Array 和 reflect.Slice 就需要遍历它的长度 val.Len(),使用 val.Index(index).Interface() 来获取它的值,至于它的元素是什么值呢? 对了,还是判断它的类型,所以要完成一个对象的反射遍历,必然是一个递归函数。
对 reflect.Struct 的处理也很特殊,它的字段数由 val.NumField() 函数获取,字段由 val.Field(index) 来获取,同样的对 reflect.Map 需要使用 val.MapKeys() 获取键集合,val.MapIndex(key) 来获取键对应的值。
总结一下大概需要分 5 种情况处理:
- 数值型的 reflect.Int、reflect.Uint、reflect.Float、reflect.Complex
- 布尔和字符串 reflect.Bool、reflect.String
- 集合 reflect.Array、reflect.Slice
- 键值对 reflect.Map
- 特殊的 reflect.Ptr、refelect.Interface、reflect.Chan、reflect.Func
func reflectIterate(x interface{}, handler func(val int)) {
val := getReflectValue(x)
switch val.Kind() {
case reflect.Int, reflect.Uint, reflect.Float32, reflect.Complex64:
// 其他不同位数的数值类型
// 以简单值调用 handler
case reflect.Bool:
// 以简单值调用 handler
case reflect.String:
// 以简单值调用 handler
case reflect.Interface:
// 特殊的
case reflect.Chan:
// 特殊的
case reflect.Func:
// 特殊的
case reflect.Struct:
for i := 0; i < val.NumField(); i++ {
reflectIterate(val.Field(i).Interface(), handler)
}
case reflect.Slice, reflect.Array:
for i := 0; i < val.Len(); i++ {
reflectIterate(val.Index(i).Interface(), handler)
}
case reflect.Map:
for _, key := range val.MapKeys() {
reflectIterate(val.MapIndex(key).Interface(), handler)
}
}
}
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/13-inside-reflect
14-常用的标准库和设计
只是学习编程语言的特性做不出有用的功能,还需要访问操作系统提供的接口才行。go 语言操作系统的接口都封装到包里,典型比如的 io、os 、time 和 syscall,此外字符串处理、压缩、编码、加解密、数学、算法也基本上每个程序都会用到的功能,本章分别举例来介绍它们。
访问 https://go.dev/ 输入 io 进行搜索,发现内置的包主要是 io 和 ioutil,事实上还有一个 bufio,io 包提供了 I/O 输入输出最基本的几口,ioutil 把基本的操作封装成了易用的函数集,而 bufio 是带有缓冲特性的处理功能。

上面三个包的浏览地址: https://pkg.go.dev/iohttps://pkg.go.dev/io/ioutilhttps://pkg.go.dev/bufio
要了解一个包的使用方法,最好的方式是先看它定义了那些接口,用 io 包举例: 
可以发现最基本的接口是 Reader、Writer、Closer、Seeker、ReaderAt、ReaderFrom、WriterAt、WriterTo 等,其他的接口是这些接口的组合或者是针对某种类型的特殊处理,比如 ReadWriteCloser 接口,它有三个接口合并而成:
type ReadWriteCloser interface {
Reader
Writer
Closer
}
而 ByteReader 是每次读下一个字节,它和 Reader 接口的定义区别是:
type Reader interface {
Read(p []byte) (n int, err error)
}
type ByteReader interface {
ReadByte() (byte, error)
}
所以在任何需要 io.Reader 的地方,都可以传递实现了 Read([]byte) 方法的实例,凡是需要 io.ByteReader 的地方都可以传递实现了 ReadByte() 方法的实例,定义一个测试 reader 接口的函数如下:
func readFromReaderInstance(reader io.Reader, size int) {
buf := make([]byte, size)
readed, err := reader.Read(buf)
if err != nil {
fmt.Printf("read err: %\n", err)
}
fmt.Printf("%d bytes readed, content: %s\n", readed, string(buf[:readed]))
}
os.Open 打开的文件对象 *File 实现了 io.Reader 接口,因此可以把它打开的文件对象传给 readFromReaderInstance 函数:
fileReader, err := os.Open("/tmp/test.txt")
defer fileReader.Close() // Close 里会判断是否为 nil,不需要放在 if 后面
if err != nil {
fmt.Printf("open file err: %s", err)
}
readFromReaderInstance(fileReader, 100) 由于 strings.NewReader 可以从一段字符串里构造出 reader 对象,因此也很容易调用:
strReader := strings.NewReader("i am string")
readFromReaderInstance(strReader, 100)
甚至可以自己定义一个实现了 io.Reader 接口的对象传给它,添加如下代码:
//MyReader 自定义实现了 Reader 接口的对象
type MyReader struct{}
func (mr *MyReader) Read(p []byte) (n int, err error) {
copy(p, []byte("hello"))
return 5, nil
}
这个 MyReader 对象每次读取的时候都固定的返回 hello 文本,共 5 个字节,调用很简单:
myReader := &MyReader{}
readFromReaderInstance(myReader, 100)
如果从终端读取用于的输入,也能使用到 io.Reader 吗? 可以,代码如下:
readFromReaderInstance(os.Stdin, 100)
os.Stdin 是什么? 学习 linux 的时候还记得 0 1 2 吗? 分别对应标准输入、标准输出、错误输出,在 os.Stdin 上按 F12 查看,发现定义如下:
// src/os/file.go
var (
Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin")
Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout")
Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr")
)
// src/syscall/syscall_unix.go
var (
Stdin = 0
Stdout = 1
Stderr = 2
)
原来是把标准的输入、输出、错误都包装了成了 *File 文件对象,难怪也支持 Read([]byte) (int, error) 读取方法,从这里也可以看出 syscall 这个包是更加底层的一个包,os 的很多易用的功能建立在 syscall 包之上。
有 Reader 就有 Writer,Writer 对函数的要求和 Reader 一样。
type Writer interface {
Write(p []byte) (n int, err error)
}
经常使用的 Fprintln 和 Printf 都是对 os.Stdout 的参数调用,因为 os.Stdout 实现了 Writer 接口,它的实现如下:
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
常用的同时实现了 io.Reader 和 io.Writer 接口的有 os.File、bufio.Reader/Writer、bytes.Buffer、gzip.Reader/Writer、cipher.StreamReader/StreamWriter、tls.Conn、csv.Reader/Writer、net.Conn 等。
如果需要一次性的读完或者写完的操作,建议使用 ReaderFrom 和 WriterTo 接口,它们分别定义了 ReadFrom 和 WriteTo 接口,用于一次性的处理数据,ReadFrom 遇到 io.EOF 结束标志后正常停止,WriteTo 写入返回的字节数,库函数 ioutil.ReadFile 就利用了 bytes.Buffer 的 ReadFrom 来读取整个文件,它内部的 readAll 方法实现:
// r 是 os.Open 后的 *File 对象
func readAll(r io.Reader, capacity int64) (b []byte, err error) {
var buf bytes.Buffer
defer func() {
// 错误处理(略)
}()
if int64(int(capacity)) == capacity {
buf.Grow(int(capacity))
}
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
下面的例子从文件中读取内容追加到字节缓冲区里:
func AppendFileContentTest() {
file, err := os.Open("/tmp/test.txt")
defer file.Close()
if err != nil {
fmt.Printf("open file err: %s", err)
}
buf := bytes.NewBufferString("hello world, from file:")
buf.ReadFrom(file) // bytes.Buffer 实现了 ReadFrom 接口,而 *File 实现了 Reader 接口
fmt.Println(buf.String())
}
io.Reader 和 io.Writer 对读写进行了简洁的定义,但是在处理数据的时候,经常需要进行偏移量读取,就可以考虑 ReaderAt、WriterAt、Seeker 接口,这三个接口都可以实现偏移量的功能,不过 Seeker 接口要更加灵活一下,它定义的 Seek 方法:
type Seeker interface {
Seek(offset int64, whence int) (ret int64, err error)
}
其中第二个参数 whence 表示了相对位置:
- io.SeekStart 相对于文件的开头
- io.SeekCurrent 相当于当前的偏移位置
- io.SeekEnd 相对于文件结束
下面的示例代码分别从尾部读取和从开头,都是读取的中间那个汉字:
func MoveSeekPosTest() {
reader := strings.NewReader("中国人第一")
reader.Seek(-9, io.SeekEnd) // 注意 UTF-8 编码,相当于 3*X 个字节移动
r, _, _ := reader.ReadRune()
fmt.Printf("%c\n", r) // 人
reader.Seek(6, io.SeekStart)
r, _, _ = reader.ReadRune()
fmt.Printf("%c\n", r) // 人
}
和这些接口比较,Closer 接口最简单,用于关闭数据流,只有一个 Close 方法,经常用在 defer 语句里,当要关闭的资源是 nil 的时候,Close 函数可能会返回 error 对象 ErrInvalid,所以调用的时候不用担心 file 是否为 nil,把 defer 直接写在后面会显得逻辑更紧凑一些,下面第一种写法更好。
// 第一种
file, err := os.Open("/tmp/test.txt")
defer file.Close()
if err != nil {
// 打开文件失败了
}
// 第二种
file, err := os.Open("/tmp/test.txt")
if err != nil {
// 打开文件失败了
}
defer file.Close()
ByteReader 和 ByteWriter 每次读写只能是一个字节,在压缩和数据包协议里会用的比较多。
而 ByteScanner 和 RuneScanner 接口就比较有意思,它们都内部含有一个 Reader 接口,比如 ByteScanner 的定义如下:
type ByteScanner interface {
ByteReader
UnreadByte() error
}
也就是比 ByteReader 多了一个 UnreadByte 函数,它的作用是把上一次 ReadByte 读取的字节再放回去,再次调用 ReadByte 和上一次的结果是一样的,所以它的规则就是调用了 ReadByte 之后才能用,而且不能连续的调用 UnreadByte,RuneReader 和 RuneScanner 是类似的作用,但它作用于 Unicode 字符。这种回退机制有时候在解析数据包协议的时候特别有用。
此外 io 包还定义了一些结构体类型:
- SectionReader 内嵌 ReaderAt 接口,可以设置便宜后读取指定的字节数
- LimitedReader 内嵌了 Reader 接口,每次读了后都更新一下剩余的可读字节数
- PipeReader 和 PipeWriter 管道读写
几个重要的函数:
- Copy 和 CopyN,拷贝数据,从 Reader 到 Writer
- ReadAtLeast 至少读多少个字节,ReadFull 将传递的 buf 读满
- WriteString 对 []byte 的包装,等同于操作 []byte(string) 参数
- MultiReader 和 MultiWriter 在逻辑上合并多个 Reader/Writer
- TeeReader 和 tee 命令类似,把 Reader 中的内容自动写入到 Writer 中
bufio 对 io.Reader 和 io.Writer 进行了包装,提供了带缓存的实现,可以由 NewReader、NewReaderSize 构建,NewReader 函数以 4096 的默认换冲区大小来调用 NewReaderSize 实现,提供了 ReadSlice、ReadByte(s)、ReadString、ReadLine、ReadRune、Peek、Reset、UnreadByte、UnreadRune、WriteTo 等方法。bufio 还提供了 Scanner 专门处理一行、分隔的输入问题,它使用内部的 split 函数辅助分割 token 标识符,split 函数又是一个 SplitFunc 对象:
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error) 该函数暴露到包外,可以独立使用,在使用 Scanner 的 Scan 函数之前,一定要调用 Split 函数,它的作用是指明要分割的规则,比如 bufio.ScanWords 按单词分割、bufio.ScanLines 按行分割等。
func CountWordsTest(input string) {
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(bufio.ScanWords)
total := 0
// 返回 false 时停止扫描,可能扫描完了,也可能是出错了
// 需要判断 Err() 函数的值来确定
for scanner.Scan() {
total++
}
// 不会是 io.EOF 错误
if err := scanner.Err(); err != nil {
fmt.Println("出错了:" + err.Error())
}
fmt.Printf("包含 %d 个单词\n", total)
}
os 包的作用是封装一些跨平台的功能,它依赖于 syscall 包,不过 os 能完成的时候尽量不要去调用 syscall 包,处理文件系统、权限、用户等,有时候需要 path 包来协助,path 包对不同的系统的路径处理提供了有用的函数,比如 windows 以 \ 分割路径,而 *nix 系统以 / 分割路径,还有相对路径、..、盘符等,如果自行拼接路径可能造成程序兼容性差,在 mac 上运行好好的,放到 windows 就异常了。
日期时间处理由 time 包完成,time 包很重要,基本上每个程序都会用,它的主要类型有:
- Location 时区
- Time 时间点
- Duration 时间段,以纳秒为单位
- Timer、Ticker 计时器
直接调用 time.Now() 即可获得当前时间,两个时间差就是 time.Duration 对象,直接打印 Duration 对象会输出可阅读的时分秒,因为 Duration 实现了 fmt.Stringer 接口:
t1, _ := time.Parse("2006-01-02 15:04:05", "2020-12-31 23:59:59")
d1 := now.Sub(t1)
fmt.Println(d1) // 125h50m8.589151s
Duration 的定义其实是一个 64 位的整数:
type Duration int64
对日期的增减通过 Sub、Add、AddDate 实现,用 Before、After 判断大小,增加 1 年的时间:
now := time.Now()
fmt.Println(now.AddDate(1, 0, 0))
fmt.Println(now.Add(time.Duration(365 * 24 * 60 * 60 * 1000000000)))
需要返回整点、整分除了可以使用 Format("2006-01-02 12:00:00") 这种形式也可以直接调用函数 Round、Truncate,经常调用的还有 time.Sleep 函数,它会挂起当前 goroutine 到指定的时间,计时器 Timer、Ticker 和通道 chan 有关,简单的理解就是用于消息通讯,<- signal 等待 signal 有消息取出来,关键字 go func() {...} () 表示开启一个协程 goroutine 让 go 运行时进行调度,注意的是对 ticker 对象需调用 Stop 来释放资源,想一直运行可以直接使用 time.Tick 来得到计时器,不过它只是 NewTicker 函数的简单包装,会一直运行下去直到进程退出。有关通道的知识下一章详细学习。
//TimerAfterTest 计时器
func TimerAfterTest() {
signal := time.After(1 * time.Second)
select {
case <-signal:
fmt.Println("到时间了...")
case <-time.After(2 * time.Second):
fmt.Println("超过2秒了...")
}
time.AfterFunc(1*time.Second, func() {
fmt.Println("我1秒后打印")
})
}
// TickerTest 定时器
func TickerTest() {
ticker := time.NewTicker(1 * time.Second)
done := make(chan bool)
go func() {
time.Sleep(3 * time.Second)
done <- true
}()
for {
select {
case <-done:
ticker.Stop()
return
case <-ticker.C:
fmt.Println("时间它滴答滴答滴")
}
}
}
处理文本的包主要由 strings、bytes、strconv、regexp、unicode 几个包完成,默认的 strings.Index 返回的是 ASCII 编码的索引,UTF-8 的版本需要借助于 utf8.RuneCountInString 函数实现:
func Utf8Index(str, substr string) int {
index := strings.Index(str, substr)
if index < 0 {
return -1
}
return utf8.RuneCountInString(str[:index])
}
fmt.Println(strings.Index("都是NO.1中国人", "中国")) // 10
fmt.Println(strlib.Utf8Index("都是NO.1中国人", "中国")) // 6
此外还有 encoding、compress、archive、math、crypto、sort 等,需要使用的时候去 go.dev 查询包的文档,下面是计算 md5 编码的例子:
func GetStrMD5(str string) string {
r := md5.Sum([]byte(str))
return hex.EncodeToString(r[:])
}
自定义排序需要实现 sort.Interface 接口,它有三个方法:
- len 长度
- swap 交换 2 个值
- less 比大小
比如实现按照年龄排序:
type PersonSlice []*Person
func (ps PersonSlice) Len() int {
return len(ps)
}
func (ps PersonSlice) Swap(i, j int) {
ps[i], ps[j] = ps[j], ps[i]
}
func (ps PersonSlice) Less(i, j int) bool {
// 顺序
return ps[j].Age > ps[i].Age
}
测试代码:
func SortPersonTest() {
persons := PersonSlice{
&Person{"zhangsan", 27},
&Person{"lisi", 22},
&Person{"wangwu", 38},
}
sort.Sort(persons)
for _, person := range persons {
fmt.Println(*person)
}
}
包里很多功能还没有介绍,经常浏览 go 的官方包和源代码,会有意想不到的收获。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/14-about-std-lib
15-使用协程和并发通道
本章将学习 go 语言和其他语言最大的不同,在语法级别支持并发操作(天生),并发编程的门槛是很高的,通常写高质量的并发代码并不是那么容易,但是 golang 把这个难度降低了,让程序员写出高性能而且易于理解不绕口的并发代码。
系统调度的单位是线程,而线程的上下文切换是非常消耗资源的,协程非常的轻量,并且它对系统来说是透明的,它属于 go 运行时来管理,在普通的函数前加一个 go 关键字,就可以创建一个协程,对,就这么简单,不需要关心线程池、状态等复杂的概念,go 的抢占式调度会帮你安排好一切,由于协程创建的代价太小了,一个线程可能会占用 2M 的内存空间,而一个协程起步只需要 2K(随着栈增长会增加),所以你可以创建几百上千万的协程,而且你根本不需要一个协程池。
不过要掌握好 go 的并发,也需要好好学习它的调度模型(GMP)和用法。下面的代码创建了 2 个协程:
func main() {
go func() {} ()
}
一个是 main,一个是匿名的 func。
func main() {
go func() {
fmt.Println("我来自协程")
}()
fmt.Println("wait...")
// select {}
time.Sleep(3 * time.Second)
}
上面的输出结果是:
wait...
我来自协程
// 顺序不保证,也可能打印
我来自协程
wait...
使用 time.Sleep 的原因是协程虽然轻量,但是调度和执行也是需要时间的,为了让 main 不要退出的太快让协会程有机会运行(正式场景不会这样用),如果去掉 go 关键字,那么匿名函数会先执行才能打印 wait... 完全是按顺序执行的,如果在循环里那就是挨个循环执行,但如果加上 go 关键字,就创建了 N 个协程并发执行,时间将会大大缩短。修改一下代码:
func main() {
for i := 0; i < 10; i++ {
go func(index int) {
fmt.Printf("我来自协程 %d\n", index)
time.Sleep(1 * time.Second)
}(i)
}
fmt.Println("wait...")
// select {}
time.Sleep(3 * time.Second)
}
试试去掉 go 关键字,你发现打印的顺序是一定的,而且时间比加上 go 关键字要长很多,这就是并发的优势,不过这里 time.Sleep 的 3秒钟实在是太丑了,更大的问题是万一创建了 N 个协程,3 秒内还没有完成呢? 改成 5 秒,7 秒? 显然不 OK,因为我们需要对协程做的工作是否完成有个监控,使用 sync.WaitGroup 可以轻松的完成这个工作。修改一下:
var wg sync.WaitGroup
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 对协程进行计数
go func(index int) {
fmt.Printf("我来自协程 %d\n", index)
wg.Done() // 通知一下,本协程把问题搞完了
}(i)
}
fmt.Println("wait...")
wg.Wait() // 等待所有的协程通知我
}
现在好了,使用全局的 wg 变量类通讯,不但并发高效的完成了工作,而且 main 也能及时退出了。WaitGroup 通过对协程同步计数来完成任务,这些协程之间本身并不认识,如果协程和协程需要通讯怎么办? 比如,一个做饭,一个吃饭,吃饭的总得等着做饭的把饭做好吧。别急,先回到上一章节等待时间的例子:
func timeAfterTest() {
deadline := time.After(1 * time.Second)
fmt.Printf("%T\n", deadline) // <-chan time.Time
select {
case <-deadline:
fmt.Println("到时间了")
}
}
发现了一个新的类型: chan,chan 表示通道/信道(就像水管,里面流淌着数据流),chan time.Time 表示通道里的数据类型是 time.Time,<- chan time.Time 表示通道里可以拿出来 time.Time 数据,select 一直等待着 deadline 里留出 time.Time 数据,等到了 case 分支就被执行了,这个机制实现了 main 和时间倒计数协程的通讯,因为 select 本身是阻塞的,deadline 没有通知 case 无法运行,select 就无法结束。
所以,通道就是协程用来通讯的机制,它本身是一个容器,这个容器有大小,可以打开、可以关闭。我们使用通道来模拟吃饭的例子:
func produce(ready chan bool) {
fmt.Println("做饭中...")
time.Sleep(50 * time.Microsecond)
ready <- true
}
func eatTest() {
ready := make(chan bool) // 无缓冲
go produce(ready) // 去掉 go 死锁
for {
select {
case <-ready:
fmt.Println("可以吃了")
return
default:
fmt.Println("我先干点别的事")
}
}
}
上面代码的细节:
- 使用 make 函数来构造 chan 类型的变量,省略第二个参数表示通道没有缓冲,没有缓冲的意思就是发送和接受两方必须同步交接
- for 是个死循环,当 <- ready 不能交接的时候,执行 default 分支,有交接了 return 结束了整个函数
- 使用 go produce(ready) 来创建做饭的协程,而且看出 chan 是引用传递,如果去掉 go 关键字 ready,ready<- true 放不进去因为没有同步的接收方,导致死锁
- chan 类型的变量是同步安全的,由 go 运行时来保证,写代码不需要考虑它被多个协程都同步修改的情况
如果理解有困难,把代码精简一下:
func eatTest2() {
ready := make(chan bool) // 无缓冲
go produce(ready) // 去掉 go 死锁
<-ready // 同步交接
fmt.Println("可以吃了")
}
记住,无缓冲的通道必须同步交接,没有接收方发送方也无法把数据放进通道中,main 中的 <- ready 试图从 ready 通道中拿点数据,但是 produce 函数还没有准备好,main 就阻塞了(如果先是 produce 执行到了也阻塞等带 main),执行到 ready <- true 的时候两边都准备好,同步交接完成,main 和 produce 继续往下执行。
这里 <- ready 并没有去关心通道里的值究竟是多少,如果 produce 函数把通道 close 了(close 函数导致通道广播),<-ready 也能收到信号,但是关闭的通道不能再打开了。
如果要模拟做饭失败的情况修改如下:
func produce2(ready chan bool) {
fmt.Println("做饭中...")
// 做饭成功的与否的算法
success := false
if time.Now().Second()%2 == 0 {
success = true
}
ready <- success
}
func eatTest3() {
ready := make(chan bool) // 无缓冲
go produce2(ready) // 去掉 go 死锁
success := <-ready // 同步交接
//success, ok := <-ready // 关闭的通道 ok 为 false
if success {
fmt.Println("可以吃了")
} else {
fmt.Println("喝西北风")
}
}
操作符 <- 看起来点绕,如果 chan 变量在左边 chanVar <- xx 表示写入,在右边 <- chanVar 表示读取,可见 -< 是指数据流向的方向。上面的 chan 通道都是无缓冲的,相对的有缓冲的通道需要给 make 第二个参数。
ready := make(chan bool) // 1
ready := make(chan bool, 0) // 2
ready := make(chan bool, 1) // 3
1 和 2 是相同的,都表示无缓冲的通道,3 不同,他是有缓冲的,通道的容量是 1,表示最多可以暂存 1 个数据在里面,下面这个例子帮助理解:
func createBufChanVar() {
//channel := make(chan string)
channel := make(chan string, 1)
go func() {
fmt.Println(<-channel)
}()
channel <- "我来啦"
// 死锁
//channel <- "我来啦"
//channel <- "我来啦"
//fatal error: all goroutines are asleep - deadlock!
for i := 0; i < 10; i++ {
fmt.Printf("for 循环 %d\n", i)
time.Sleep(1 * time.Second)
}
}
如果 channel 是无缓冲的,那么执行到 channel <- "我来啦" 会阻塞,一直等到 go func 执行到 <- channel 同步交接数据,"我来啦" 永远会打印在 for 循环前面,但如果 channel 是有缓冲的,channel <- "我来啦" 可以把数据放进通道继续往后执行,这时候 for 循环可能会先打印,如果连续的三条 channel <- "我来啦" 程序就会发生死锁,因为第一次放进去,go func 取走了一个,通道空了还可以放一个但是没有谁会再取走了,再次执行 channel <- "我来啦" 后阻塞,因为通道大小是 1,再也放不下了,go 运行时检测到死锁,程序崩溃。
所以有缓冲的通道,通道中没有塞满的时候不会发生阻塞,如果通道满了,放入数据就会阻塞,如果通道空了,取数据就会阻塞,发送方和接受方在交接数据的时候不需要同步准备好,不用同时见面就可以完成数据交换,但是无缓冲的通道就必须面对面交易,等我来验货不然你就给我等着,因为交易地点没有暂存货物的地方。
回到本文开始,time.After 返回的类型是 <- chan time.Time,这是只读通道,只能发出数据,同样的 chan <- time.Time 就是只写通道,只能接收数据,这两种都叫单向通道,可读可写的就是双向通道。
你可能认为有缓冲的通道比无缓冲的通道有用,事实并非如此,它们都有各自的应用场景,可以使用熟悉的 len 和 cap 函数获取通道当前的数据流长度和容量。
func lenCap() {
d1 := make(chan int)
d2 := make(chan int, 3)
d2 <- 1
fmt.Println(len(d1), cap(d1)) // 0 0
fmt.Println(len(d2), cap(d2)) // 1 3
}
有缓冲的通道的数据流可以使用 for-range 读取,一直到通道关闭为止。
func forRangeChan() {
queue := make(chan string, 3)
go func() {
queue <- "one"
queue <- "two"
queue <- "three"
close(queue) // 去掉 close for-range 将死锁
}()
for elem := range queue {
fmt.Println(elem)
}
}
看看下面的官网的打印斐波那契数列的例子:
func fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c) // 一定要 close,不然 for-range 会阻塞死锁
}
func main() {
c := make(chan int, 10)
go fibonacci(cap(c), c)
for i := range c {
fmt.Println(i)
}
}
有时候我们不关心 chan 通道里的值,就像做饭的第一个例子一样,只想表示某件事或者某个状态达成了,可以使用 chan struct {},通过结构体章节的学习知道 struct {} 空结构体是内存空间的,会被编译器特殊处理,它的内存地址固定的。做一个简单的服务器,这个服务器唯一的功能就是打印字符串和序号:
//server 服务实例
type server struct {
stopFlag chan struct{}
waitGroup sync.WaitGroup
}
//Work 做事
func (s *server) Work(index int) {
time.Sleep(50 * time.Microsecond)
fmt.Printf("干活儿 %d\n", index)
}
//Stop 停止
func (s *server) Stop() {
close(s.stopFlag) // 直接关闭通道
s.waitGroup.Wait() // 等带 handle 的 goroutine 都正常结束
}
func (s *server) handle(index int) {
s.waitGroup.Add(1)
go func() {
for {
select {
case <-s.stopFlag:
fmt.Printf("handle %d over", index)
s.waitGroup.Done()
return
default:
s.Work(index)
}
}
}()
}
按照 go 预言的习惯,添加一个工场函数:
func newServer() *server {
return &server{make(chan struct{}), sync.WaitGroup{}}
}
下面的代码创建 server 后,给它分配一点儿的工作,在 500 毫秒后通知它停下来:
func createServerTest() {
srv := newServer()
for i := 0; i < 3; i++ {
srv.handle(i)
}
select {
case <-time.After(500 * time.Microsecond):
srv.Stop()
}
}
这个服务器的例子使用无缓冲的通道实现了 "是否应该停止服务" 这个事件的通讯,很多编程语言中多个线程传递数据的方式是共享内存,因此需要对内存进行读写保护,go 语言也支持这种共享内存的模型,但是更提倡使用通讯顺序进程 CSP 来完并发操作,goroutine 就是 CSP 模型里的实体,chan 就是 CSP 模型里的传递信息的媒介,也就是 goroutine 通过 chan 来完成通讯(数据传递)。
通道 chan 通讯前面已经有很多例子了,相信你已经理解了,下面举例一个 chan 锁定的例子,它并不用来通讯,只用来保存一段指令对内存的操作。代码的功能是完成循环计数,不过你多次运行发现它并不能得到正确的结果,理论上应该得到 100,但是运行可能出现 99、98 等。
func inc(x *int) {
*x = *x + 1
}
func sumByLoop() {
x := 0
for i := 0; i < 100; i++ {
go inc(&x)
}
// 为了代码结构简洁,简单的加个停顿(应该使用 sync.waitGroup 实现)
time.Sleep(1 * time.Second)
fmt.Println(x)
}
因为 *x = *x + 1 不是原子操作,它点读取 x,累加后再写入,多个协程工作的时候,有的协程读取了老的 x 累加后会写入把其他协程的累加计数覆盖了,所以最终的结果可能小于 100,下面是修改后的版本,使用一个容量大小是 1 的有缓冲通道,来控制 *x = *x + 1,此处的 chan 并没有用来传递数据:
func inc(x *int, lock chan struct{}) {
lock <- struct{}{}
*x = *x + 1
<-lock
}
func sumByLoop() {
x := 0
lock := make(chan struct{}, 1)
for i := 0; i < 100; i++ {
go inc(&x, lock)
}
// 为了代码结构简洁,简单的加个停顿(应该使用 sync.waitGroup 实现)
time.Sleep(1 * time.Second)
fmt.Println(x)
}
再来运行,每次都是 100 了,因为建立的是有缓冲的通道,执行 lock <- struct{}{} 后,还能继续往下运行,又因为缓冲通道的大小只有 1,上一个协程在没有执行 <-lock 将通道清空之前,其他的协程只能等着把 struct{}{} 放进去,这样执行 *x = *x +1 的永远只有一个协程,保护了这段内存空间的操作,这是一个典型的互斥锁,可直接使用系统提供的 sync.Mutex 来实现:
func inc2(x *int, mutex *sync.Mutex) {
mutex.Lock()
*x = *x + 1
mutex.Unlock()
}
func sumByLoop2() {
x := 0
mutex := &sync.Mutex{}
for i := 0; i < 100; i++ {
go inc2(&x, mutex)
}
// 为了代码结构简洁,简单的加个停顿(应该使用 sync.waitGroup 实现)
time.Sleep(1 * time.Second)
fmt.Println(x)
}
回到协程通道的话题,有没有发现常见一个协程后,无法主动的强制去关闭它,最优雅的方式就是通知它让它自己退出,或者整个进程退出了。当需要管理很多个协程的状态(和很多子协程),使用 context 包也许更加清晰明了,它的接口申明如下:
type Context interface {
Deadline() (deadline time.Time, ok bool) // 到期时间
Done() <-chan struct{} // 做完了
Err() error // 报错信息
Value(key interface{}) interface{} // 绑定的值
}
Context 的几个构造函数:
- context.WithCancel
- context.WithDeadline
- context.WithTimeout
- context.WithValue
它们的第一个参数都是父 context,默认 context.Background 是根 context,根 context 不能不取消。
模仿前面 server 的功能:
func handle(ctx context.Context, index int) {
for {
select {
case <-ctx.Done():
fmt.Printf("handle %d over", index)
return
default:
fmt.Printf("干活了 %d\n", index)
}
}
}
func contextServerTest() {
ctx, cancel := context.WithCancel(context.Background())
for i := 0; i < 3; i++ {
go handle(ctx, i)
}
time.Sleep(1 * time.Second)
cancel() // 可以 defer cancel
time.Sleep(1 * time.Second)
}
服务器开启了 3 个协程工作,1 秒后手动 cancel 通知他们停下来,如果超时自动 cancel 可以使用 context.WithTimeout 或者 context.WithDeadline,一个是相对时间,一个绝对时间:
func contextServerTest2() {
ctx, _ := context.WithTimeout(context.Background(), 1*time.Second)
//ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
//cancel() // 仍然可以手动提前结束
for i := 0; i < 3; i++ {
go handle(ctx, i)
}
time.Sleep(2 * time.Second)
}
不过这两个例子并没有演示 context 的优势,稍微修改一下,当父 context 被 cancel 的时候,子 context 也会遭殃,这样 goroutine 就好管理了,如此推导,是不是就理解了?
func contextServerTest3() {
parent, parentCancel := context.WithCancel(context.Background())
ctx1, _ := context.WithCancel(parent)
ctx2, _ := context.WithTimeout(parent, 10*time.Second)
for i := 0; i < 3; i++ {
go handle(ctx1, i)
}
for i := 3; i < 6; i++ {
go handle(ctx2, i)
}
time.Sleep(1 * time.Second)
parentCancel() // 子 ctx1,ctx2 也会遭殃
time.Sleep(1 * time.Second)
}
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/15-goroutine-support
16-并发任务的固定模式
虽然我们可以自己使用 chan 来实现很多并发的框架和模式,但实际应用的时候先查查 sync 包总是没错的,比如 sync/atomic 包对原子操作进行了支持,上一个章节的 *x = *x +1,其实可以直接使用 atomic.AddUint64(&x, 1) 来实现。
标准库 sync.Once 可以实现只执行一次的功能,比如你指向创建一个对象(单件)。下面这个 born 函数永远只会造同一个人:
type person struct{}
var instance *person
var once sync.Once
func born() *person {
once.Do(func() {
fmt.Println("构建 instance 对象")
instance = &person{}
})
return instance
}
我们启动 10 个 goroutine 来测试一下:
func getInstance() {
wg := sync.WaitGroup{}
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
instance := born()
fmt.Printf("%p\n", instance) // 0x1254790
}()
}
wg.Wait()
}
每次获取到的 instance 的地址都是一样的,说明是同一个对象,它的实现机制如下:
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
首先是对通过 mutex 和 atomic.StoreUint32 配合来实现,看到这里 doSlow 函数就奇怪了,你不是有 mutex 吗? 为什么还要来一发 aotmic 的函数操作呢? doSlow 函数名其实已经说明了一切。doSlow 说明这个函数很慢,因为 mutex 是一个成本很高的操作,而整数的原子读写却轻量很多,所以 atomic.LoadUint32 先判断了一下 o.done 是不是为 0,不是的话就滚蛋了,少量的竞争者最后能到达 if o.done == 0 的判断,这个提前的判断提高了性能(请注意 defer 语句执行的顺序,对 mutex 解锁 Unlock 比设置 o.done 为 1 的操作后执行。
sync/atomic 不仅能对基本的数值类型进行原子操作,atomic.Value 还能对 interface{} 数据类型进行操作。
既然系统包这么好用,为什么不把所有的应用模式封装完呢? 有时候系统包并不好用,看下面的 mutex 的例子:
func main() {
var mu sync.Mutex
go func(){
fmt.Println("NO.1中国人")
mu.Lock()
}()
mu.Unlock()
}
程序的意图简洁清晰明了,看起来好像没有什么问题,但是执行大概率是报错:
fatal error: sync: unlock of unlocked mutex
因为 go func 的 goroutine 和 main 的 goroutine 执行顺序并不能保证谁先谁后,mu.Unlock 的时候 mu.Lock 还未执行,所以 Unlock 直接抛出了错误。要修改它也很麻烦,要这样写:
func main() {
var mu sync.Mutex
mu.Lock
go func(){
fmt.Println("NO.1中国人")
mu.Unock()
}()
mu.lock()
}
是不是不好理解? 第二个 mu.Lock 的时候会等着 mu.Unlock 先执行,有点绕口。但是如果使用无缓冲的通道来重构代码不但简单而且很可靠:
func main() {
exit := make(chan int)
go func() {
fmt.Println("NO.1中国人")
<-exit
}()
exit <- 1
}
为什么很可靠? 因为 exit 没有缓冲,不管 exit <- 1 先执行到 还是 <-exit 先执行到,都得等待同步交接,咱们谁先到都见面聊。这个例子中 <- exit 和 exit <- 1 的位置可以交换,他们的读写本身并没有意义,chan 的类型也是无意义的,用 string、struct{} 都行,但是 chan 完成了比 mutex 很易懂的代码。把这个例子扩展一下,启动指定数量的任务:
func lockBatch(taskCount int) {
waitGroup := make(chan struct{}, taskCount)
for i := 0; i < cap(waitGroup); i++ {
go func(index int) {
fmt.Printf("NO.1中国人%d\n", index)
waitGroup <- struct{}{}
}(i)
}
for i := 0; i < cap(waitGroup); i++ {
<-waitGroup
}
}
这不就是 sync.WaitGroup 干的事情吗? 这就是框架,或者说模式。
这个模式可以启动 N 个协程,来做 N 件事情,每个协程和任务的比例是 1:1,不过太多的协程可能不利于管理和回收,能不能抽象出 N 个协程做 M 件事情的模式呢? 为了让 goroutine 可以不断的做任务,可以使用一个有缓冲的通道来保存任务,极端的情况是只有一个 goroutine 来做任务,它不断的从缓冲通道里取出任务执行,知道通道关闭为止,由于不同的 goroutine 可以安全的从通道中读取任务,因此可以随意调节 goroutine 的数目而不用修改代码。定一个 handle 函数表示做任务的工人:
var wg sync.WaitGroup
func handle(tasks chan string, index int) {
defer wg.Done()
for {
// 读取关闭的无缓冲通道,返回零值和false
// 读取关闭的有缓冲通道,先把缓存数据读完后,再读取返回零值和false
task, ok := <-tasks
if !ok {
// 任务通道关闭了,不会再有新任务了
fmt.Printf("handle %d over\n", index)
return
}
fmt.Printf("干活儿 %s By 工人 %d\n", task, index)
}
}
tasks 表示任务的需求,如果只需要一个工人,直接 go handle 就行了,多个工人只需一个循环,工人下班的标志依靠 wg 来保证,干完活就能下班,而 tasks 通道用来接收任务。
func createTasks(goroutines, taskCount int) {
tasks := make(chan string, taskCount)
// 启动 N
wg.Add(goroutines)
for i := 0; i < goroutines; i++ {
go handle(tasks, i)
}
// 设置 M
for k := 0; k <= taskCount; k++ {
tasks <- fmt.Sprintf("任务 %d", k)
}
close(tasks)
wg.Wait()
}
参数 goroutines 是工人的个数(协程的个数),而 taskCount 是任务的数量。需要注意的时候,在通道 close 关闭后,通道中的数据依然可以读取直到读完后再次读取事 task 是零值(这里是空字符串,因为 chan 的类型是 string),ok 为 false,也就是没有任务了,工人都可以下班了(wg.Done),而 wg.Wait 会等所有工人都下班后,才把工厂的门关上(函数返回)。如此,就完成了 N:M 的任务模型,这里 N 和 M 可以通过调用参数传递数量,而你不用修改内部的代码。
进一步延伸这个例子,就是生产者和消费者,而生产者和消费者的数量可以是任何比例。
func producer(name string, tasks chan<- string) {
index := 0
for {
tasks <- fmt.Sprintf("%s-task-%d", name, index)
time.Sleep(50 * time.Millisecond)
index++
}
}
func consumer(name string, tasks <-chan string) {
for task := range tasks {
fmt.Printf("%s-%s has been token\n", name, task)
time.Sleep(50 * time.Millisecond)
}
}
producer 生产者是个是循环,源源不断的造东西,而 consumer 一直从 tasks 里取货,模拟一个工厂的代码:
func createFactory(stockSize, producerCount, consumerCount int) {
tasks := make(chan string, stockSize)
for i := 0; i <= producerCount; i++ {
go producer(fmt.Sprintf("p%d", i), tasks)
}
for i := 0; i <= consumerCount; i++ {
go consumer(fmt.Sprintf("c%d", i), tasks)
}
exit := make(chan os.Signal, 1)
// ctrl+c 中断程序
signal.Notify(exit, syscall.SIGINT, syscall.SIGTERM)
<-exit
}
stockSize 是车间大小,表示了最多能存多少货,producerCount 是生产者个数,consumerCount 是消费者个数,当生产者 pdoducer 足够多的时候,把仓库 stockSize 塞满了就阻塞了没法再生产了,除非消费者 consumer 来拿走一些;反之如果消费者足够多的时候,仓库里没货也只能等着了,除非生产者 producer 造点货出来。
为了达到平衡,如果希望生产者以稳定的效率工作,不多不少,如何控制呢? 非常简单:
func producer2(max int, tasks chan<- string, doSth func() string) {
lines := make(chan int, max)
for {
lines <- 1
tasks <- doSth()
<-lines
}
}
max 表示最大的生产线,每次开一个生产线,就往通道里计数一个,生产完了,再从通道取出一个,因为通道最大是 max,满了就阻塞了,随时都保证了只有 max 条生产线存在。
下面的这个例子实现的功能是,等待一个对象完成自己的工作,和前面不同的是,它把 chan 的状态作为对象的一部分:
type request struct {
data []interface{} // 模拟要处理的数据
finish chan struct{} // 完成后的标志
}
func newRequest(data ...interface{}) *request {
return &request{data, make(chan struct{}, 1)}
}
func doWork(req *request) {
time.Sleep(1 * time.Second) // 模拟耗时
fmt.Println(req.data) // 工作内容就是打印
close(req.finish) // req.finish <- struct{}{} 也行
}
func createWork() {
req := newRequest(1, "string", true)
go doWork(req)
for i := 0; i < 100; i++ {
time.Sleep(50 * time.Millisecond)
fmt.Println("继续做事,我很忙")
}
<-req.finish
}
createWork 函数通过并发提高了处理效率,单独开了一条线去处理 request,同时它可以继续往后做事,但是它保证在函数返回前 req 对象肯定被处理了。关于 chan 和并发,还有很多有用的固定模式,希望这几个例子可以抛砖引玉。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/16-concurrent-pattern
17-网络编程和服务器
在 OSI 七层网络模型中,HTTP、DNS、FTP 等协议属于应用层的,往下 TCP、UDP 属于传输层协议,再往下是 IP、ICMP 等协议,通常说的网络编程主要基于 TCP、UDP 以及基于上层协议的应用。
在网络中依靠 IP 地址可以识别到一台主机,要定位都进程还需要加上端口号,两个不同主机上的进程要通讯还得语言互通,这就是协议。这种通讯在编程里经常成为 socket 编程,翻译为套接字编程,它把应用层和传输层中间做了一个抽象,把 TCP/IP 的复杂概念抽象成几个函数接口定义,实现了不同主机之间的进程通讯。这个 socket 套接字首先是在伯克利 BSD 系统里发扬光大,socket 本意是插座,有人觉得翻译为套接口更合适,既然是抽象的接口,也就是你不管使用哪个编程语言,都是一样的编程套路。
下面的代码演示了如何建一个 tcp 的服务端,它的作用是为客户端提供时间查询服务。
func handleClient(conn net.Conn) {
defer conn.Close()
str := fmt.Sprintf("%s\n", time.Now().Format("2006-01-02 15:04:05"))
conn.Write([]byte(str))
}
func startTcpServer() {
listener, _ := net.Listen("tcp", "127.0.0.1:3000")
defer listener.Close()
for {
conn, _ := listener.Accept()
go handleClient(conn)
}
}
为了简化代码,没有进行错误判断,startTcpServer 执行后开始 listen 监听本地的 3000 端口,然后陷入死循环等待客户端来连接,特别要注意的是 listen.Accept() 的调用将会等待连接,当有客户端连接的会后被系统唤醒,这时候将获得一个 net.Conn 对象,然后启动了一个协程去为客户端服务,因为 go 关键字的便利性,它已经可以和多个客户端通讯了,把当前时间通过 net.Conn 写入到套接字数据缓冲区后,它主动的关闭了 tcp 连接。
怎么测试呢? 不用着急写一个客户端,我们先用 telnet 命令来测试一下:
Desktop 🍎 telnet 127.0.0.1 3000
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
2021-01-09 17:09:00Connection closed by foreign host.
打印时间后,telnet 提示 "Connection closed by foreign host",说明的确远程 server 主动把连接 close 掉了。
net.Listen 返回的是 net.Listener 接口对象,它定义了三个方法:
type Listener interface {
Accept() (Conn, error)
Close() error
Addr() Addr
}
Accept 函数执行后得到 net.Conn 接口对象,它定义了如下方法:
type Conn interface {
Read(b []byte) (n int, err error) // 读
Write(b []byte) (n int, err error) // 写
Close() error // 关闭
LocalAddr() Addr // 本地通讯地址
RemoteAddr() Addr // 远端通讯地址
SetDeadline(t time.Time) error // 设置不活跃时保持连接的时间
SetReadDeadline(t time.Time) error
SetWriteDeadline(t time.Time) error
}
总结一下编写 Tcp Server 的套路:
- 获得一个 Listener 监听对象
- 调用 Accept 等待客户端来连接
- 连接建立后后往 Conn 对象里读和写数据
- 不需要的时候可主动关闭连接
相对于 server 编写 client 则更加简单:
func startTcpClient() {
conn, _ := net.Dial("tcp", "127.0.0.1:3000")
buf := make([]byte, 100)
conn.Read(buf)
fmt.Println(string(buf))
}
使用 net.Dial 函数,请求与本机 3000 端口建立套接字连接,成功后获得 net.TCPConn 对象,接着从里面读取数据显示出来。
不过这两个例子太过于简单,真实的 tcp 通讯程序面临很多问题:
- 服务端开启等待时候,可能端口被占用了或者被防火墙阻止,造成启动服务端失败
- 由于 Server 端的负载能力或者网络不稳定,可能客户端请求建立连接会失败
- 建立连接后,网络不稳定 Read 和 Write 函数可能不会按预期那样工作
- tcp 是面向连接的协议,往往需要多次读写,但是每次读写的数据不一定是完整的业务内容(粘包、丢包)
- 建立好的连接也可能因为网络因素被断开,需要实现心跳和自动重连机制保证软件的可用性
上面的代码看起来是顺序编程,很多语言编写高性能的网络程序,需要多进程+多线程+非阻塞 I/O 多路复用来实现,但在 go 运行时这一层,通过对 goroutine 和非阻塞 I/O 多路复用机制的抽象,真实的底层 socket 对象是非阻塞的,go 运行时拦截了底层的 socket 调用,通过调度 goroutine 来简化了用户层的代码编写,比如对 socket 发起 read 读数据操作,如果对应的 socket 文件描述符并没有数据可读,go 运行时把 socket 文件描述符加入监听器,同时 goroutine 也会被挂起,当 go 运行时收到了 socket 文件描述符 ready 的通知后,会立刻唤醒挂起的 goroutine,这个过程在读取 goroutine 的角度来看,好像自己被阻塞住了。
加一个循环来测试一下多客户端的情况:
func startTcpClient2() {
for i := 0; i < 1024; i++ {
conn, _ := net.Dial("tcp", "127.0.0.1:3000")
log.Println(conn.LocalAddr().String() + " dial at " + time.Now().Format("15:04:05"))
}
}
客户端建立连接后,我们打印出了本地通讯地址和建立连接的时间,为了程序运行的慢一点,给 Server 端加一个延迟,修改如下:
func startTcpServer2() {
listener, _ := net.Listen("tcp", "127.0.0.1:3000")
defer listener.Close()
for {
time.Sleep(5 * time.Second)
conn, _ := listener.Accept()
log.Println("Accept at " + time.Now().Format("15:04:05"))
go handleClient(conn)
}
}
服务端每 5 秒钟获取到一个客户端连接,测试代码:
func Test_acceptBacklog(t *testing.T) {
go startTcpServer2()
startTcpClient2()
}
启动客户端以后输出类似如下:
......
2021/01/10 13:05:09 127.0.0.1:61901 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61902 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61903 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61904 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61905 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61906 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61907 dial at 13:05:09
2021/01/10 13:05:09 127.0.0.1:61908 dial at 13:05:09
2021/01/10 13:05:14 Accept at 13:05:14
2021/01/10 13:05:15 127.0.0.1:61909 dial at 13:05:15
2021/01/10 13:05:19 Accept at 13:05:19
2021/01/10 13:05:19 127.0.0.1:61917 dial at 13:05:19
2021/01/10 13:05:24 Accept at 13:05:24
......
有没有发现很奇怪,客户端的 dial 在开始的时候很快建立了连接,但是到后来每隔 5 秒钟才能建立一个新链接,很奇怪吧? 这说明客户端的 dial 建立连接的行为和服务端的 accept 行为并不是同步的。事实上 accept 只是从建立好的连接里取出一个来,而同时等待 accept 处理的连接数受到系统的限制,在 mac 是上它的值是 kern.ipc.somaxconn,默认是 128 个,也就是服务端没有被 accept 的连接数最大是 128 个,所以一开始 server 端很快收到了 client 客户端的 128 个连接,客户端 dial 几乎立即成功,但是 server 端每隔 5 秒后才 accept 取出来一个连接进行处理,处理一个后才有一个坑位挪出来,所以达到 kern.ipc.somaxconn 的限制后 client 需要隔上 5 秒才能成功建立连接。
如果服务端一直没有坑位,那么客户端 dial 会发生超时错误。
func startTcpServer3() {
listener, _ := net.Listen("tcp", "127.0.0.1:3000")
defer listener.Close()
select {}
}
func startTcpClient3() {
for i := 0; i < 1024; i++ {
_, err := net.Dial("tcp", "127.0.0.1:3000")
// 设置超时时间
//_, err := net.DialTimeout("tcp", "127.0.0.1:3000", 1*time.Second)
if err != nil {
fmt.Println(err)
} else {
fmt.Println("dial at " + time.Now().Format("2006-01-02 15:04:05"))
}
}
}
控制超时的等待时间可以使用 net.DialTimeout 函数,没有坑位的时候 dial 开始报超时错了:
......
dial at 2021-01-10 14:47:04
dial at 2021-01-10 14:47:04
dial at 2021-01-10 14:47:04
dial tcp 127.0.0.1:3000: i/o timeout
dial tcp 127.0.0.1:3000: i/o timeout
dial tcp 127.0.0.1:3000: i/o timeout
......
同样的读写也会有时间超时的问题,读写超时的时间使用以下三个函数设置:
- SetDeadline(t time.Time)
- SetReadDeadline(t time.Time)
- SetWriteDeadline(t time.Time)
参数是一个 time.Time 类型,也就是从连接被 accept 到数据被完全读取必须在这个时间点内,因为它是一个准确的时间点,所以在每次读写之前都需要为其设置新的时间点。看下面这个例子:
func startServerWithTimeout() {
listener, _ := net.Listen("tcp", "127.0.0.1:3000")
defer listener.Close()
for {
conn, _ := listener.Accept()
conn.SetDeadline(time.Now().Add(3 * time.Second))
c := &client{conn, 3}
go handle(c)
}
}
接受连接后设置读写超时的时间是 3 秒钟,看看 handle 函数的处理:
type client struct {
conn net.Conn
timeout int
}
func handle(c *client) {
buf := make([]byte, 100)
for {
size, err := c.conn.Read(buf)
if err != nil || size == 0 {
fmt.Println(err)
c.conn.Close()
return
}
c.conn.SetDeadline(time.Now().Add(3 * time.Second))
fmt.Println(string(buf))
}
}
如果读成功了,就继续续命 3 秒,如果都失败了,就把链接关闭了。启动后用 telnet 连接,如果 3 秒钟输入任何字符回车发送给 server 端,那么连接可以一直存活下去,如果 3 秒内无数据,服务端显示 i/o timeout 然后连接被强行关闭。修改一下程序,使用通道来实现类似的功能,首先为 client 对象增加一个通道成员用于通讯:
type client struct {
conn net.Conn
activeChan chan struct{}
timeout int
}
在 handle 每次读成功后都给通道发送一个信号:
func handle(c *client) {
for {
buf := make([]byte, 100)
size, err := c.conn.Read(buf)
if err == nil || size > 0 {
c.activeChan <- struct{}{}
fmt.Println(string(buf))
}
}
}
增加一个 goroutine 专门用于检测是否收到了信号,在指定的超时时间内没有信号,则主动关闭连接:
func alive(c *client) {
for {
select {
case <-c.activeChan:
fmt.Println("keep alive")
case <-time.After(time.Duration(c.timeout) * time.Second):
c.conn.Write([]byte("goodbye\n"))
c.conn.Close()
}
}
}
启动服务器的代码如下,每次 accept 时,启动 2 个 goroutine 来服务一个客户端:
func startServerWithTimeout() {
listener, _ := net.Listen("tcp", "127.0.0.1:3000")
defer listener.Close()
for {
conn, _ := listener.Accept()
c := &client{conn, make(chan struct{}), 3}
go handle(c)
go alive(c)
}
}
使用 telnet 测试,3 秒内输入任意字符都可续命,否则超时被关闭,在 alive 中其实可以做很多需要成功读取后要处理的业务,通道的作用其实把连接读写的细节、业务处理、连接状态维护解耦了,这个模式很有用,在 go 网络编程中很常见。
tcp 是面向连接的通讯,适用于对数据传输要求非常高的场景,但是有些业务比如聊天、视频可以忽略偶尔的传输错误,这时候使用 udp 协议更为合适,它定义了无需连接就可以发送 IP 数据包的方法,一个客户端可以向任意的不同的服务器发送数据。
定义一个 udp server 如下:
func startUdpServer() {
listener, _ := net.ListenUDP("udp", &net.UDPAddr{IP: net.ParseIP("127.0.0.1"), Port: 3000})
buf := make([]byte, 100)
for {
size, remoteAddr, err := listener.ReadFromUDP(buf)
if err == nil && size > 0 {
fmt.Println(remoteAddr.String())
fmt.Println(string(buf))
}
}
}
由于没有事前建立连接,udp 客户端在发送数据的时候需要指明本机的地址和远端的地址:
func startUdpClient() {
ip := net.ParseIP("127.0.0.1")
// 自动分配
// local := &net.UDPAddr{IP: net.IPv4zero, Port: 1110}
local := &net.UDPAddr{IP: ip, Port: 3001}
remote := &net.UDPAddr{IP: ip, Port: 3000}
conn, _ := net.DialUDP("udp", local, remote)
defer conn.Close()
conn.Write([]byte("can you hear me?\n"))
}
创建一个 http 应用服务器则比 tcp 和 udp 更加简单,毕竟它是最上层的一个封装:
func startHttpServer() {
http.HandleFunc("/time", func(writer http.ResponseWriter, request *http.Request) {
writer.Write([]byte(time.Now().String()))
})
http.HandleFunc("/headers", func(writer http.ResponseWriter, request *http.Request) {
for key, headers := range request.Header {
for _, val := range headers {
fmt.Fprintf(writer, "%v:%v\n", key, val)
}
}
})
http.ListenAndServe(":3000", nil)
}
请求的对象被抽象成 http.Request,响应对象被抽象为 http.ResponseWriter,2 个路由:
- /time 打印当前服务器时间
- /headers 打印请求的 http 头
下面是 http.ListenAndServe 的实现:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
定义了一个 http.Server 结构体,调用它的同名方法,实现如下:
func (srv *Server) ListenAndServe() error {
if srv.shuttingDown() {
return ErrServerClosed
}
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(ln)
}
本质还是启动一个 tcp 服务器,大量的工作都是在处理 http 协议头和对客户端响应数据(http.Request 对象比 http.ResponseWriter 对象复杂的多),根据这个原理,你可以实现一个自己的 http 服务器。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/17-network-socket
18-工程和包管理系统
在教程一开始就介绍了 go mod 命令,它用于管理项目的依赖项,在当前目录输入 "go mod init 模块名称" 初始化 go.mod 文件,比如想用 github.com/fatih/color 包,在项目根目录下输入:
go get github.com/fatih/color
// 输出
go: downloading github.com/fatih/color v1.10.0
go: github.com/fatih/color upgrade => v1.10.0
go: downloading github.com/mattn/go-colorable v0.1.8
go: downloading golang.org/x/sys v0.0.0-20200223170610-d5e6a3e2c0ae
此时项目根目录下多了一个 go.sum 文件,记录了 color 包以及它本身的依赖,并锁定了相关的版本,为了同一个项目的开发人员有用一致的依赖和版本,该文件通常需要加入到 git 版本仓库中。
下载了依赖项,在项目里可作为模块来调用了。
import "github.com/fatih/color"
func main() {
color.Cyan("我是 cyan")
color.Red("我是 red")
}
可以通过执行 go list -m all 或者 go mod graph 来查看当前项目的依赖项。输入 go help mod 查看 mod 相关的命令:
download download modules to local cache
edit edit go.mod from tools or scripts
graph print module requirement graph
init initialize new module in current directory
tidy add missing and remove unused modules
vendor make vendored copy of dependencies
verify verify dependencies have expected content
why explain why packages or modules are needed
比如 go mod vendor 命令,可以在当前目录新建一个目录 vendor,里面是一份项目依赖模块的源代码拷贝(通常该目录不要加入 git 版本库,在 .gitignore 中设置忽略,注释生成 vendor 后模块调用会优先找到 vendor 下的代码进行编译)。
如何发布一个模块到 github 给别人使用呢?
- 使用 go mod init github.com/你的github账号名/你的模块名
- 实现模块和编写测试代码
- 编写文档 README.MD 以及相关的脚本
- 在 github.com 新建远端仓库
- 给你的项目打上 tag 标签推送至远端仓库
- 在其他项目里执行 go get github.com/你的github账号名/你的模块名 导入使用
写一个密码生成器的 module 试试,新建目录 password-generator,执行 git mod init github.com/developdeveloper/password-generator 后,指定如下目录:
├── cmd
│ ├── char
│ │ └── main.go
│ └── digit
│ └── main.go
├── go.mod
├── internal
│ ├── randnum.go
│ └── randnum_test.go
├── pkg
│ ├── pwdgen.go
│ └── pwdgen_test.go
cmd 是生成可执行文件的主程序,internal 目录是模块内部使用的代码,pkg 是模块暴露到外部的代码(通常 pkg 下应该还要建立包,由于代码太简单就省略了),生成密码的函数需要产生随机值,internal 目录实现了 RandNumber 函数:
func RandNumber(max int) int {
rand.Seed(time.Now().UnixNano())
return rand.Int() % max
}
定义的密码生成器结构体:
func New() *PasswordGenerator {
return &PasswordGenerator{}
}
生成数字密码:
func (pg *PasswordGenerator) DigitsOnly(length int) string {
var buf bytes.Buffer
digits := "0123456789"
for i := 0; i < length; i++ {
buf.WriteByte(digits[internal.RandNumber(10)])
}
return buf.String()
}
生成字符密码:
func (pg *PasswordGenerator) CharsOnly(length int) string {
var buf bytes.Buffer
chars := "abcdefghijklmnopkrstuvwxyz"
for i := 0; i < length; i++ {
buf.WriteByte(chars[internal.RandNumber(26)])
}
return buf.String()
}
执行 git 命令:
git add .
git ci -m 'initial'
git tag v1.0
git remote add origin git@github.com:developdeveloper/password-generator.git
git push -u origin master
git push --tags
访问 https://github.com/developdeveloper/password-generator,我们写的密码生成器模块已经上传到 github 了,其他项目可以安装使用了,进入本章节的项目目录,执行 go get github.com/devellopdeveloer/password-generator 创建依赖和下载包:
go get github.com/developdeveloper/password-generator
go: downloading github.com/developdeveloper/password-generator v0.0.0-20210111081505-6237ddb53d37
go: github.com/developdeveloper/password-generator upgrade => v0.0.0-20210111081505-6237ddb53d3
修改 main.go 代码:
import (
passwordGenerator "github.com/developdeveloper/password-generator/pkg" // 包的别名
"github.com/fatih/color"
)
func main() {
//color.Cyan("我是 cyan")
//color.Red("我是 red")
pwdGen := passwordGenerator.New()
color.Green(pwdGen.DigitsOnly(6))
color.Blue(pwdGen.CharsOnly(6))
}
恩,我们写的 module 可以工作了,go 语言本身并没有对工程的目录做出限定,不过通常会使用以下的目录结构:
cmd 可执行文件,可能有多个 main 文件
internal 内部的代码,私有类型和函数
pkg 公开的类型和函数
configs 加载配置
deploy 部署相关的定义
githooks git的钩子
scripts bash脚本
init 初始化函数
vendor 依赖的拷贝
build 持续集成相关的
examples 说明的示例程序
test 测试文件
testdata 测试数据
web 网页相关的模板等
api 开放的 api 接口
docs 文档
assets 图片等资源
README.md 项目说明文件
third_party 外部辅助工具
tools 项目的支持工具
Makefile 脚本运行的入口
bin 编译好的二进制文件
LICENSE.md 版本申明文件
要特别的提示一下,用过 Java、Node 等编程语言的同学,通常项目里会有 src 这个目录,go 项目里不建议这样做。
本章节的代码
- https://github.com/developdeveloper/password-generator
- https://github.com/developdeveloper/go-demo/tree/master/18-project-and-package
19-Web 开发和中间件
回顾一下前面在网络编程中启动 http 服务器的代码,其实只需要一行:
http.ListenAndServe(":3000", nil)
访问本机的 3000 端口,你会收到:
404 page not found
收到 404 http 的状态码,说明服务器已经正常启动,但是没有任何的路由处理器,所以返回了 404,看看 http.ListenAndServe 函数的签名和实现:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
构建了一个 http.Server 对象,Server 结构第一个是 Addr 对象(string),第二个是 Handler 对象。
type Server struct {
Addr string
Handler Handler // handler to invoke, http.DefaultServeMux if nil
......
}
Addr 是一个字符串表示地址和端口,Handler 是什么呢? 继续 F12 查看:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
原来是一个实现了 ServeHTTP 函数的接口对象,这个接口恰好就是对 http 请求和响应的封装,而且 Server 的结构有个注释,如果第二个参数是 nil,那么对应的 Handler 对象就是 http.DefaultServeMux,查看 Server 的 ServeHTTP 方法,源代码如下:
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
if req.RequestURI == "*" && req.Method == "OPTIONS" {
handler = globalOptionsHandler{}
}
handler.ServeHTTP(rw, req)
}
继续跟踪 DefaultServeMux 发现它是 &defaultServeMux 的引用:
var DefaultServeMux = &defaultServeMux
var defaultServeMux ServeMux
继续跟踪 ServeMux 发现它的 ServeHTTP 方法实现最后被 NotFoundHandler 所处理,难怪是 404:
func NotFound(w ResponseWriter, r *Request) { Error(w, "404 page not found", StatusNotFound) }
func NotFoundHandler() Handler { return HandlerFunc(NotFound) }
直接调用 http.HandleFunc 也是作用在这个 defaultServeMux上。 所以要对请求做处理,其实做一个实现了 ServeHTTP 方法的接口对象就行了,它可以安全被转换为 http.Handler 对象,作为一个适配器,http.HandlerFunc 是 http.Handler 的单函数类型适配,也就是说除了让结构体实现 ServeHTTP 方法外,你可以直接提供一个签名为 http.HandlerFunc 的函数作为处理器:
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
小结一下,第一种是提供 http.Handler 对象,然后使用 http.Handler(string,Handler) 来挂载处理器;第二种是提供 http.HandlerFunc(ResponseWriter, *Request) 签名的函数,它们共同的目的都是为了得到一个 ServeHTTP(ResponseWriter, *Request) 函数。
内置的 mux 对路由的支持很简单,在 API 的开发中,很多都遵守 RESTFUL 的设计理念,这时候解析 *Request 的路由就成了很大的体力活儿,需要借助 github.com/julienschmidt/httprouter 模块来帮忙,httprouter 并不是框架,先安装它。
go get github.com/julienschmidt/httprouter
go: downloading github.com/julienschmidt/httprouter v1.3.0
go: github.com/julienschmidt/httprouter upgrade => v1.3.0
它的用法很简单:
router := httprouter.New()
router.GET("/", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {})
用 httprouter 封装后的处理,相比 ServeHTTP 多了 httprouter.Params 对象,它的定义如下:
type Param struct {
Key string
Value string
}
type Params []Param
定义如下的路由:
func main() {
router := httprouter.New()
router.GET("/:name", func(w http.ResponseWriter, r *http.Request, ps httprouter.Params) {
fmt.Fprintln(w, fmt.Sprintf("%s 你好!", ps.ByName("name")))
})
http.ListenAndServe(":3000", router)
}
其中 :name 成为路径命令参数,访问 http://localhost:3000/zhangsan 显示 "zhangsan 你好!",查看 GET 的定义,发现 httpRouter 定义了自己的 Handle 处理器:
type Handle func(http.ResponseWriter, *http.Request, Params)
Params 的作用就是解析各种路由参数,包括通配符匹配等,其内部使用了压缩字典树结构,这种数据结构的特点是可以高效的做字符串检索,很多 web 框架都使用了 httprouter,比如 https://github.com/gin-gonic/gin,实现和前面相同功能的例子:
func startGinServer() {
router := gin.New() // 干净的没有中间件
// router := gin.Default() // 会包含 logger 和 recover 中间件
router.GET("/:name", func(c *gin.Context) {
c.String(http.StatusOK, "%s 你好!", c.Params.ByName("name"))
})
router.Run(":3000")
}
框架 gin 进一步把 Server 的概念抽象成了 gin.Engine,把请求的上下文抽象成了 gin.Context,提供了输入、输出、插件、验证、安全等很多实用的功能,如果你要做一个正式的 web 项目,可以考虑从 gin 开始。
有了 http.HandlerFunc 和 ServeHTTP 的知识,就可以写 http 中间件了。因为 Handler 的原理是提供函数 func(ResponseWriter, *Request),所以可以提供一个中间件返回这样的函数就行了,其实就是返回 http.Handler,又因为对别的 Handler 的处理其实就是调用 ServeHTTP 方法,所以中间件的函数可以层层包装,在内部实现对 ServeHTTP 的调用,顺便干一点别的事情。简言之,中间件函数的输入是一个 http.Handler,返回也是一个 http.Handler,下面的中间件会在真正要处理的 handler 调用前和完成后打印一个时间点:
func loggerMiddleware(real http.Handler) http.Handler {
return http.HandlerFunc(func(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintln(writer, "before "+time.Now().String())
real.ServeHTTP(writer, request)
fmt.Fprintln(writer, "\nafter "+time.Now().String())
})
}
它的用法如下:
func startMiddlewareServer() {
serve1 := func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("我前后有时间"))
}
handler := http.HandlerFunc(serve1)
http.Handle("/1", loggerMiddleware(handler))
serve2 := func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("我前后也有时间"))
}
http.Handle("/2", loggerMiddleware(http.HandlerFunc(serve2)))
//http.HandleFunc("/2", loggerMiddleware(http.HandlerFunc(serve2)).ServeHTTP)
http.ListenAndServe(":3000", nil)
}
访问 http://localhost:3000/1 输出:
before 2021-01-12 11:56:11.26169 +0800 CST m=+233.747613357
我前后有时间
after 2021-01-12 11:56:11.261703 +0800 CST m=+233.747626890
访问 http://localhost:3000/2 输出:
before 2021-01-12 11:56:50.768871 +0800 CST m=+273.255964104
我前后也有时间
after 2021-01-12 11:56:50.768895 +0800 CST m=+273.255988769
中间件运行的顺序是:
request -> logger-before => real.ServeHTTP => logger-after -> response
如果再包一层中间件:
request -> newMiddleware-before => logger-before => real.ServeHTTP => logger-after => newMiddleware-after -> response
所以中间件是一个洋葱皮的模型,一层一层的,洋葱皮的中心就是被最终包装的 ServeHTTP,外层两边都只是辅助打酱油的,进一步把中间件的类型重新定义一下:
type middleware func(handler http.Handler) http.Handler
中间件就是 middleware 类型的数组,查看 gin.Default() 函数发现它加载中间价的写法是:
engine := New()
engine.Use(Logger(), Recovery())
Logger 和 Recovery 函数都返回 HandlerFunc,Use 函数的参数是 ...HandlerFunc,它在内部使用 append 把所有的 HandlerFunc 都 append 到列表 Handlers 上,形成了新的 HandlersChain 调用链:
type HandlersChain []HandlerFunc
最后通过 gin.Engine 的 addRoute 方法映射到路径上:
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
// ...
}
这个 engine 最后怎么被使用的呢? 它其实就是 http.ListenAndServe 的第二个参数,没错,它本身也作为一个 http.Handler 介入,在 ServeHTTP 里完成分发请求和响应。
// router.Run(":3000")
func (engine *Engine) Run(addr ...string) (err error) {
defer func() {
debugPrintError(err)
}()
address := resolveAddress(addr)
debugPrint("Listening and serving HTTP on %s\n", address)
err = http.ListenAndServe(address, engine)
return
}
// Engine as http.Handler
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
c := engine.pool.Get().(*Context) // 使用了 sync.Pool 减少分配和回收,并发安全
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c) // 最后调用点集大成者在此
engine.pool.Put(c)
}
到目前为止,应该可以基于 httprouter 写一个能支持 middleware 的 web 简略框架了。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/19-web-and-middleware
20-使用 RPC 远程调用
RPC 意为远程过程调用或者远程方法调用,这里说的远程可能是本机的另外一个进程,但大多场景是远程的一台 tcp 服务器,Web HTTP Api 访问虽然方便,但是面对复杂的业务的时候封装查询参数往往就很复杂了,RPC 调用在调用方生成动态代理接口对象,调用远程的方法就就像是调用本地方法一样,提高了易用性。
动态代理接口对象的主要工作是:
- 识别要访问的远程方法的 IP 和端口
- 将调用方法名、参数进行序列化
- 将通讯的请求发送给远端服务器
- 接受远程服务器返回的调用结果
这个过程比较重要的是通讯协议和序列化协议,通讯就是 tcp 连接通讯,而序列化是将对象的状态信息转换为可传输和可存储的过程,反序化就是从这些可传输、可存储的数据中恢复对象实例和它的状态,甚至是方法定义。在 go 语言中,这个过程使用 encoding/gob 完成,gob 对 go 就像 Serialization 对 java、pickle 对 python,这些序列化方案都是语言内部的,需要跨语言的描述就需要 xml、json、protocol buffers 序列化方案了。
下面的例子把 person 结构体实例序列化到终端显示,由于序列化的结果并不全是文本,所以显示不规整:
type person struct {
Name string
Age int
}
p1 := person{"zhangsan", 20}
enc1 := gob.NewEncoder(os.Stdout)
enc1.Encode(p1)
当然也能存成文件:
file1, _ := os.OpenFile("/tmp/person.gob", os.O_CREATE|os.O_WRONLY, 0644)
enc2 := gob.NewEncoder(file1)
enc2.Encode(p1)
file1.Close()
这时候如果把 /tmp/person.gob 通过 qq 传给好友,那么好友也能读取这个文件恢复成一个 person 结构体对象:
var p2 person
file2, _ := os.Open("/tmp/person.gob")
defer file2.Close()
dec := gob.NewDecoder(file2)
dec.Decode(&p2)
在 PRC 远程调用的过程中,对象也是通过被序列化后通过网络传输给服务方,服务方把序列化的数据恢复成对应的结构体对象,用传过来的参数调用它的方法后返回结果,调用方只需要知道方法的签名就行了,不必知道它的具体实现过程,这个叫存根(stub)。
go 语言的 net/rpc 包提供了编写 RPC 调用的支持,首先定义一下 rpc 的服务端,它是真正提供实现的一方:
type HelloService struct{}
func (hs *HelloService) Say(name string, reply *string) error {
*reply = "hi, " + name
return nil
}
func startHelloRpcServer() {
rpc.RegisterName("HelloService", new(HelloService))
listener, _ := net.Listen("tcp", ":3000")
//使用 for 循环服务多个客户端
conn, _ := listener.Accept()
rpc.ServeConn(conn)
}
新的方法是 rpc.RegisterName 和 rpc.ServeConn,先注册 rpc 的服务名(RegisterName 用于指定名称,Register 函数利用反射获得名称),然后使用 conn 连接构造 rpc 服务,事实上 ServeConn 函数接受的参数类型是 io.ReadWriteCloser,F12 查看 ServeConn 的内部实现,可以看到 gob 编解码:
func ServeConn(conn io.ReadWriteCloser) {
DefaultServer.ServeConn(conn)
}
func (server *Server) ServeConn(conn io.ReadWriteCloser) {
buf := bufio.NewWriter(conn)
srv := &gobServerCodec{
rwc: conn,
dec: gob.NewDecoder(conn),
enc: gob.NewEncoder(buf),
encBuf: buf,
}
server.ServeCodec(srv)
}
在内部它调用了 ServeCodec 来实现,这个函数接受一个 ServerCodec 对象,表示具体使用哪一种序列化的编解码方案,这里默认的是 gob,而 gob 是 go 语言内部的,它不能跨语言,如果需要以 json 序列化传输对象和参数,就可以直接使用这个函数:
// rpc.ServeConn(conn)
// 使用 json 编码
rpc.ServeCodec(jsonrpc.NewServerCodec(conn))
而 json 序列化的实现是:
func NewServerCodec(conn io.ReadWriteCloser) rpc.ServerCodec {
return &serverCodec{
dec: json.NewDecoder(conn),
enc: json.NewEncoder(conn),
c: conn,
pending: make(map[uint64]*json.RawMessage),
}
}
有了 rpc 的服务端,客户端就可以调用了,很显然就像网络编程一样,客户端需要先 dial 到服务方建一个连接,然后把调用的方法名和参数都序列化后传过去:
var reply string
client, _ := rpc.Dial("tcp", "127.0.0.1:3000")
client.Call("HelloService.Say", "zhangsan", &reply)
fmt.Println(reply)
// client.Call 真正调用了远程方法,第一参数是方法名,第二个是调用参数,它对应着服务方的第一个参数,第三个参数是调用结果,对应服务方的第二个参数,F12 查看 Call 的实现:
func (client *Client) Call(serviceMethod string, args interface{}, reply interface{}) error {
call := <-client.Go(serviceMethod, args, reply, make(chan *Call, 1)).Done
return call.Error
}
它在内部通过 Go 函数实现,返回了一个通道一直等待,所以 Call 是一个同步调用,如果希望异步就可直接调用 Go 方法自己拿到通道进行处理:
done := client.Go("HelloService.Say", "zhangsan", &reply, nil).Done
// 继续做其它的事情
<-done
这个例子只有一个参数,如果调用需要多个参数则么办? 直接在 Say 方法中增加参数是行不通的,go 语言对 rpc 远程方法做了规定:
- 只允许有 2 个参数,第二个参数必须是指针类型
- 必须返回 error 类型
所有要支持多个参数,第一个参数必须修改成结构体类型,看下面的 math 的例子:
type MathService struct{}
func (ms *MathService) Calc(expr Expr, reply *int) error {
switch expr.Method {
case "add":
*reply = expr.Left + expr.Right
case "mul":
*reply = expr.Left * expr.Right
}
return nil
}
func startMathRpcServer() {
rpc.RegisterName("MathService", new(MathService))
listener, _ := net.Listen("tcp", ":3000")
//使用 for 循环服务多个客户端
conn, _ := listener.Accept()
rpc.ServeConn(conn)
}
这里的 Calc 是暴露的远程方法,它的第一个参数 expr 是结构体类型,定义了运算符号和操作数:
type Expr struct {
Method string
Left int
Right int
}
客户端的调用示例:
expr := Expr{"add", 1, 2}
client.Call("MathService.Calc", expr, &reply)
fmt.Println(reply)
这两个例子的服务方都是 tcp 的监听方,其实远程方法的提供者只是基于 io.ReadWriteCloser 实例,这里是 tcp.Conn 对象,所以其实 rpc 的服务方也可以是 tcp 的客户端对象,比如:
func startProxyRpcServer() {
rpc.Register(new(HelloService))
for {
// 反过来拨号到外网的 ip 地址上
conn, err := net.Dial("tcp", "127.0.0.1:3000")
// 外网客户端还未监听连接失败
if err != nil {
time.Sleep(1 * time.Second)
continue
}
rpc.ServeConn(conn)
conn.Close()
}
}
这个 tcp 一直尝试去连接本机的 3000 端口,它是 tcp 客户端,但是当连接上了,它也使用 conn 对象来提供 rpc 调用服务,完成后关闭 conn 连接,这时候客户端 rpc 的调用其实是开启 tcp 监听,它是调用方但是它不主动,等待被连接,它也不知道哪个 rpc 提供方会来服务,这个过程相当于反向代理:
func startProxyRpcClient() {
var reply string
// 外网的客户端主动提供 tcp 服务等待连接
listener, _ := net.Listen("tcp", ":3000")
conn, _ := listener.Accept()
// 构建 rpc 客户端对象
client := rpc.NewClient(conn)
defer client.Close()
client.Call("HelloService.Say", "zhangsan", &reply)
fmt.Println(reply)
}
和前面 rpc 调用方的区别是,首先使用 rpc.NewClient 构建一个 rpc 客户端对象,使用 Call 发起调用。
如果你已经写了一个 rpc 服务,现在需要提供 http 的版本怎么办? 是不是在 http 内部再调用一下 rpc 服务方呢,显然有点麻烦。能不能把在 http 的方法内直接嫁接到 rpc 服务方呢? 可以,不过这个前提是使用 xml、json 的序列化方案,go rpc 提供 ServeRequest 函数来嫁接:
func startHttpJsonRpcServer() {
rpc.RegisterName("HelloService", new(HelloService))
http.HandleFunc("/say", func(writer http.ResponseWriter, request *http.Request) {
var conn io.ReadWriteCloser = struct {
io.Writer
io.ReadCloser
}{
writer,
request.Body,
}
rpc.ServeRequest(jsonrpc.NewServerCodec(conn))
})
// curl localhost:3000/say -X POST --data '{"method":"HelloService.Say","params":["zhangsan"],"id":0}'
http.ListenAndServe(":3000", nil)
}
调用这个 http 方法的时候,需要传递序列化的调用语义:
{"method":"HelloService.Say","params":["zhangsan"],"id":0}
这里的 id 是调用的表示符,因为网络传输的原因,先发起的调用很可能后返回结果,需要一个 id 来鉴别是本次调用。
go rpc 提供了简洁的实现方案,在正式项目中常常需要跨语言的 rpc 调用,而 json 序列化的结果是全文本,传输效果过低,因此都大多使用 Protobuf 的方案,它是一个中间的描述语言,定义了调用的数据结构和消息(方法),使用编号来绑定数据,序列化后的数据字节数更少,调用方和服务方靠这个中间文件各自生成对应语言的代码,这样即实现了高效调用也实现了跨语言,具体参考 github.com/golang/protobuf/protoc-gen-go。基于 Protobuf 谷歌开发了 gRPC 开源框架,基于 http/2 协议提供服务。请注意如果不需要跨语言调用,go 自带的 net/rpc 是非常好的方案。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/20-rpc-distibuted-os
21-分布式服务框架 gRPC
gRPC 是谷歌开发的高性能、通用的开源 RPC 框架,使用 http/2 协议设计,默认基于 protobuf 序列化,gRPC 支持众多的编程语言互调。使用之前需要安装 protoc 的编译器。Protocol Buffers 是用 C++ 语言编写的,直接去 https://github.com/protocolbuffers/protobuf/releases 下载二进制版本到本地解压后,移动到系统的 bin 目录,比如 /usr/local/bin 就用了。 
Desktop 🍎 protoc --version
libprotoc 3.14.0
查看 protoc 的版本则安装成功,要生成对应语言的 proto 代码,还需要安装对应的语言的插件。执行下面的命令安装 go 语言的 protobuf 插件:
GO111MODULE=off go get github.com/golang/protobuf/protoc-gen-go
使用 which 确认一下:
Desktop 🍎 which protoc-gen-go
/Users/wangbo/.go/bin/protoc-gen-go
protobuf 最基本的数据单元叫 message,类似于结构体,不同的语言通过这个 message 定义来生成可以互相调用的代码。
看一个最简单的 hello.proto 的定义:
syntax = "proto3";
package hello; // 包名
// 定义一种 String 的类型/结构
message String {
// 成员
string value = 1; // 1 是编码时的编号
}
使用 protoc 命令生成 go 的代码:
hello[master*] 🍎 protoc --go_out=. hello.proto
hello[master*] 🍎 ll
total 8.0K
-rw-r--r-- 1 wangbo staff 2.4K 1 15 11:42 hello.pb.go
-rw-r--r-- 1 wangbo staff 72 1 15 11:42 hello.proto
--go_out 表示生成 go 语言的代码,hello.pb.go 就是其生成的文件,里面定义了 String 这个结构体,还增加了一些方法。HellService 现在可以这样写了:
type HelloService struct{}
func (hs *HelloService) Hello(name *String, reply *String) error {
reply.Value = "hi, " + name.GetValue()
return nil
}
func startHelloProtoRpcServer() {
rpc.RegisterName("HelloService", new(HelloService))
listener, _ := net.Listen("tcp", ":3000")
conn, _ := listener.Accept()
rpc.ServeConn(conn)
}
服务端和 net/rpc 版本的代码相同,客户端的代码也差不多,换成了 String 类型:
func startHelloProtoRpcClient() {
var reply String
client, _ := rpc.Dial("tcp", "127.0.0.1:3000")
client.Call("HelloService.Say", String{Value: "zhangsan"}, &reply)
fmt.Println(reply.Value)
}
这好像和自己定义一个 String 结构体没有什么区别啊? 确实,上个章节说到如果不需要跨语言用 net/rpc 就很好了,不过它演示了 protobuf 的基本用法。
下面实现一个跨语言版本的 hellorpc,对 hello.proto 增加 Say 方法的定义:
syntax = "proto3";
package grpchello;
// 调用参数
message Person {
string name = 1;
}
// 调用结果
message Result {
string text = 1;
}
// 调用方法
service HelloService {
rpc Say (Person) returns (Result);
}
生成 go 语言的定义:
protoc --go_out=plugins=grpc:. hello.go.proto
打开生成的 hello.pb.go 文件,发现除了定义 Person 和 Result 结构体外,还定义了服务端和客户端的接口:
type HelloServiceServer interface {
Say(context.Context, *Person) (*Result, error)
}
type HelloServiceClient interface {
Say(ctx context.Context, in *Person, opts ...grpc.CallOption) (*Result, error)
}
rpc 的服务方被抽象成了 grpc.Server,客户端其实是包装了 grpc.ClientConn 的对象,还提供了 rpc 的注册函数 RegisterHelloServiceServer,构造一个 grpc.Server 对象,提供一个 HelloServiceServer 的结构体实现 Say 方法就可以启动一个 grpc 的服务端了:
func startGrpcHelloServer() {
grpcServer := grpc.NewServer()
RegisterHelloServiceServer(grpcServer, new(HelloServiceServerImpl))
conn, _ := net.Listen("tcp", ":3000")
grpcServer.Serve(conn)
}
接下来做一个java 的客户端来访问它,首先也得根据 proto 文件生成 java 的代码,和 go 不同的时候,指定了 java 的 package 包名,引入依赖 protobuf-java、grpc-protobuf、grpc-stub,记得要先安装 protoc-gen-grpc-java 插件(编译参考 https://github.com/grpc/grpc-java/blob/master/compiler/README.md,下载参考 https://repo1.maven.org/maven2/io/grpc/protoc-gen-grpc-java/1.35.0/)。
mkdir -p src/main/java
protoc --java_out=src/main/java hello.java.proto
protoc --plugin=/usr/local/bin/protoc-gen-grpc-java --grpc-java_out=src/main/javahello.java.proto
生成的文件:
src/main/java
└── com
└── wangbo
└── proto
├── HelloProto.java
├── HelloService.java
├── HelloServiceGrpc.java
├── Person.java
├── PersonOrBuilder.java
├── Result.java
├── ResultOrBuilder.java
启动 java 的客户端访问 go 的服务端:
public class ClientApplication {
public static void main(String[] args) {
ManagedChannel channel = ManagedChannelBuilder
.forAddress("127.0.0.1", 3000)
.usePlaintext()
.build();
HelloServiceGrpc.HelloServiceBlockingStub stub = HelloServiceGrpc.newBlockingStub(channel);
Person person = Person.newBuilder().setName("zhangsan").build();
Result result = stub.say(person);
System.out.println(result.getText());
}
}
调用成功,如果把 go 作为客户端代码也很简单:
func startGrpcHelloClient() {
conn, _ := grpc.Dial("127.0.0.1:3000", grpc.WithInsecure())
defer conn.Close()
stub := NewHelloServiceClient(conn)
result, _ := stub.Say(context.Background(), &Person{Name: "zhangsan"}, grpc.EmptyCallOption{})
fmt.Println(result.Text)
}
对应的 java 服务端的代码,继承 HelloServiceImplBase 重载 say 方法:
public class ServerApplication {
public static void main(String[] args) throws InterruptedException, IOException {
Server server = ServerBuilder.forPort(3000)
.addService(new HelloServiceGrpc.HelloServiceImplBase() {
@Override
public void say(com.wangbo.proto.Person person, StreamObserver<com.wangbo.proto.Result> responseObserver) {
Result result = Result.newBuilder().setText("hi, " + person.getName()).build();
responseObserver.onNext(result);
responseObserver.onCompleted();
}
}).build().start();
server.awaitTermination();
}
}
这两个例子只使用 string 类型,为了跨语言,protobuf 定义了很多种数据类型,更多的用法和例子访问 https://developers.google.com/protocol-buffers/docs/reference/google.protobuf,其他语言的 grpc 参考 https://grpc.io/docs/languages,grpc 还提供了 tls 安全的通讯方案。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/21-distibuted-os-issue
22-关系型数据库访问
go 原生提供了对数据库的支持,就是 database/sql 包,对关系型的数据库进行了通用的抽象,轻量、面向行的接口,所以使用这个包还需要下载对相应的数据库驱动,比如 mysql 的驱动包 github.com/go-sql-driver/mysql,执行:
go get -u github.com/go-sql-driver/mysql
由于不需要调用驱动包的含糊,只需要其执行一次 init 函数,imoprt 部分往往是:
"database/sql"
_ "github.com/go-sql-driver/mysql"
不引入驱动,调用 sql 包的函数的时候会收到提示:
sql: unknown driver "mysql" (forgotten import?) 为什么引入 mysql 的包后就可以工作了呢? 这是因为 mysql 包里的 init 函数里执行了 sql.Register 函数:
func init() {
sql.Register("mysql", &MySQLDriver{})
}
查看 Register 函数的实现,会发现内部把驱动类型和驱动实例做了一个映射保存在 drivers 中,对 MySQLDriver 来说,就是 "mysql" => &MySQLDriver{},Register 函数的第二个参数是 driver.Driver 接口对象,它只要求实现 1 个方法:
type Driver interface {
Open(name string) (Conn, error)
}
Open 函数返回一个 driver.Conn 对象,根据注释得知该 Conn 对象在同一时间只会被一个 goroutine 所占用,通过查看 MySQLDriver 的 Open 函数发现它使用了内部的 connector 对象来实现,而 connector 对象又将功能更委托给了 mysqlConn 对象,该连接对象负责和 mysql 之间交互的协议。
sql 包使用 sql.Open 来获得一个数据库操作对象 sql.DB,而这个 DB 结构体中最重要的就是 driver.Connector,它要求实现 2 个方法:
- Connect(context.Context) (Conn, error)
- Driver() Driver
func getMysqlDB() *sql.DB {
db, _ := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?charset=utf8&parseTime=true")
//db, _ := sql.Open("mysql", "root:@tcp(127.0.0.1:3306)/test?charset=utf8mb4&parseTime=True")
//db.Ping()
return db
}
问题是这个 sql.Open 里的 connector 是怎么和 mysql 驱动的 connector 连接上的呢? F12 进入 sql.Open 函数,发现它会尝试从 dirvers 获取 MySQLDriver 的实例,尝试转换成 driver.DriverContext 后调用其 OpenConnector 函数,如果转换失败了也会构造一个内部的 dsnconnector 对象,调用 driver 上的 Open 方法。
而 MySQLDriver 对 Open 和 OpenConnector 都提供了实现:
func (d MySQLDriver) Open(dsn string) (driver.Conn, error) {
cfg, err := ParseDSN(dsn)
if err != nil {
return nil, err
}
c := &connector{
cfg: cfg,
}
return c.Connect(context.Background())
}
func (d MySQLDriver) OpenConnector(dsn string) (driver.Connector, error) {
cfg, err := ParseDSN(dsn)
if err != nil {
return nil, err
}
return &connector{
cfg: cfg,
}, nil
}
sql 包依靠 Open、Register 2 个函数实现了驱动包的注入,获得 driver.Conn 对象后,主要工作就是解析 sql 查询和获得结果了(mysql 交互协议),因为查询通常分为 2 种类型:
- query 查询带结果,比如 select 等
- exec 只需执行,比如 update、delete 等
具体 sql 包在调用时会尝试把 driver.Conn 对象转换成 Queryer、QueryerContext 和 Execer、ExecerContext 执行其对应的方法,不过这一切使用 sql.DB 做为中间对象来操作,在 DB 内部它对 driver.Conn 对象做了进一层带锁的包装 driverConn,在任何查询前都会使用 db.conn 内部方法里获取 driverConn,它从加锁以后从 freeConn 里取出一个并标记为 inUse 在使用,否则就检测是否达到最大连接数,没有就就调用 connector 对象的 Connect 方法获得 driver.Conn 后构造一个新的 driverConn,用完了后都会调用它的 relaseConn 把连接对象重新 put 回 freeConn 列表里。至此,go sql 驱动包的加载和执行的流程都清楚了。
mysql 的 go hello 版本如下:
func main() {
var str string db := getMysqlDB()
row := db.QueryRow("SELECT 'hello go-mysql'")
if row.Scan(&str) == nil {
fmt.Println(str)
}
}
批量查询和使用预编译的查询:
func scan() {
db := session.GetMysqlDB()
rows, _ := db.Query("SELECT * FROM user")
defer rows.Close()
// 遍历 rows
}
func single() {
var user User
db := session.GetMysqlDB()
db.QueryRow("SELECT * FROM user WHERE id = 1").Scan(&user.id, &user.passport, &user.password, &user.nickname, &user.createdAt)
fmt.Println(user)
}
func prepare() {
db := session.GetMysqlDB()
stmt, _ := db.Prepare("SELECT * FROM user WHERE id = ?")
defer stmt.Close()
rows, _ := stmt.Query(1)
defer rows.Close()
//
}
怎么遍历 rows 呢? 需要使用 Next() 来判断,当遇到 io.EOF 或者 rows 被 close 会结束遍历。
for rows.Next() {
var user User
rows.Scan(&user.id, &user.passport, &user.password, &user.nickname, &user.createdAt)
fmt.Println(user)
}
使用 rows.Error 来得到错误 插入时使用 LastInsertId 来获取最后一行的 id:
func main() {
db := session.GetMysqlDB()
stmt, _ := db.Prepare("INSERT INTO user(`passport`, `password`,`nickname`) VALUES(?, ?, ?)")
result, _ := stmt.Exec("lisi", "abc123", "李四")
fmt.Println(result.LastInsertId())
}
使用 begin 和 beginTx 开启一个事务,begin 使用默认的 context.Background() 来调用 beginTx,事务会独占数据库连接,但是 Tx 对象上的方法和 sql.DB 都是一一对应,调用 commit 或者 rollback 后,Tx 对象才被 Close 掉。
func main() {
db := session.GetMysqlDB()
stmt, _ := db.Prepare("INSERT INTO user(`passport`, `password`,`nickname`) VALUES(?, ?, ?)")
result, _ := stmt.Exec("lisi", "abc123", "李四")
fmt.Println(result.LastInsertId())
}
NULL 字段有时候会很麻烦,处理 NULL 有两个办法:
- 使用数据库函数 COALESCE 让可能 NULL 的字段不可能返回 NULL
- 使用 sql.NullString、sql.NullInt32 等类型
type NullString struct {
String string
Valid bool // Valid is true if String is not NULL
}
对于第二种办法,Scan 操作后需要先用 Valid 判断一下,为 true 则调用 String 或者 Value 方法,值得注意的并没有 sql.NullUint32 等类型,可以自定义 NULL 类型,实现 Scan 和 Value 方法。比如 NullInt32 的实现如下:
// NullInt32 represents an int32 that may be null.
// NullInt32 implements the Scanner interface so
// it can be used as a scan destination, similar to NullString.
type NullInt32 struct {
Int32 int32
Valid bool // Valid is true if Int32 is not NULL
}
// Scan implements the Scanner interface.
func (n *NullInt32) Scan(value interface{}) error {
if value == nil {
n.Int32, n.Valid = 0, false
return nil
}
n.Valid = true
return convertAssign(&n.Int32, value)
}
// Value implements the driver Valuer interface.
func (n NullInt32) Value() (driver.Value, error) {
if !n.Valid {
return nil, nil
}
return int64(n.Int32), nil
}
如你所见,上面的 Scan 的用法其实非常的不方便,实际项目里用 struct tag + orm 来做比较多,下面是使用 sqlx (go get https://github.com/jmoiron/sqlx) 的例子:
type User struct {
ID int `db:"id"`
Passport string `db:"passport"`
Password string `db:"password"`
Nickname string `db:"nickname"`
CreatedAt time.Time `db:"create_time"`
}
func main() {
var total int
var user User
var users []User
var names []string
db := session.GetSqlxDB()
db.Get(&total, "SELECT COUNT(*) FROM user")
fmt.Println(total)
db.Get(&user, "SELECT * FROM user LIMIT 1")
fmt.Println(user)
db.Select(&users, "SELECT * FROM user")
fmt.Println(users)
db.Select(&names, "SELECT nickname FROM user")
fmt.Println(names)
db.QueryRowx("SELECT * FROM user LIMIT 1").StructScan(&user)
fmt.Println(user)
rows, _ := db.Queryx("SELECT * FROM user")
defer rows.Close()
for rows.Next() {
var u User
rows.StructScan(&u)
fmt.Println(u)
}
}
除了好用的 Get、Select、StructScan,还有 MapScan、SliceScan 分别对应 map[string]interface{} 和 []interface{},如果需要数据库 ORM 可以关注下 https://github.com/go-gorm/gorm。
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/22-access-rdb-sql
23-非关系型数据库访问
相对于关系型 sql 数据库,nosql 数据库今年来兴起,典型的像 redis、 mongodb、leveldb、hbase、cassandra 等,nosql 横向扩展更加便捷,灵活的数据类型,无需预先建立存储字段,可自定义格式,在很多系统中除了 sql 关系型的数据,还需要部分 nosql 数据库来配合,甚至有些项目只用 nosql 库,因此熟悉一下 nosql 的访问非常有必要。
redis 提供了丰富的数据结构,除了简单的 kv 键值对,还有 list、hash、set、zset 等,支持事务和原子操作,还能使用 lua 来实现执行脚本,基本上每个项目必用。首先加入 redis 的依赖包:
go get github.com/go-redis/redis
该包对 redis 的调用主要定义了 redis.Client 对象,使用 NewClient 获得一个 redis 的客户端,值得注意的使用完以后需要调用其 Close 方法,内部使用了 baseClient 对象维护状态和连接池。
func GetRedisClient() *redis.Client {
return GetRedisClientWithDB(0)
}
func GetRedisClientWithDB(db int) *redis.Client {
return redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: db,
})}
有了 client 对象,就可以像 redis-cli 一样向 redis 服务器发送各种命令了。比如最简单的 set/set、setnx 操作:
func keyValue() {
client := session.GetRedisClient()
defer client.Close()
client.Set("one", 1, 0)
val, _ := client.Get("one").Result()
fmt.Println(val)
oldVal, _ := client.GetSet("one", "cos(0)").Result()
fmt.Println(oldVal)
val, _ = client.Get("one").Result()
fmt.Println(val)
client.Set("two", 2, 0)
client.MSet("three", 3, "four", 4, "five", 5)
vals, _ := client.MGet("one", "two", "three", "four", "five").Result()
fmt.Println(vals)
client.SetNX("once", "atomic", 0).Err()
did, _ := client.SetNX("once", "atomic", 0).Result()
fmt.Println(did)
}
对 redis 的调用结构都被封装成了 *Cmd 结构,比如 IntCmd、StringCmd、SliceCmd 等,这些 *Cmd 都嵌入了 baseCmd 结构,实现了 Cmder 接口,使用 Result() 方法获得调用结果,这个结果返回 cmd 中的 err 对象来表明错误,对应 redis 的 nil,这个包使用 redis.Nil,比如你 GET 一个不存在的 key,redis 会返回 Nil,对应包内的定义是:
const Nil = RedisError("redis: nil")
对其他数据结构类型的调用示例请参考本章节 github 上的代码,下面的例子是发布订阅模型:
func pubsub() {
client := session.GetRedisClient()
defer client.Close()
sub := client.Subscribe("channel")
go func() {
time.Sleep(1 * time.Second)
client.Publish("channel", "a message")
time.Sleep(1 * time.Second)
sub.Close()
}()
for message := range sub.Channel() {
fmt.Println(message.Channel, message.Payload)
}
}
使用 pipeline 和基于 watch 的事务:
func pipe() {
client := session.GetRedisClient()
defer client.Close()
// MULTI-DISCARD-EXEC 整体提交
// MULTI
pipe := client.TxPipeline()
pipe.Set("counter", 1, 0)
pipe.IncrBy("counter", 1)
pipe.Expire("counter", 10*time.Second)
_, err := pipe.Exec()
// EXEC
if err != nil {
fmt.Println(err)
}
}
func watch() {
client := session.GetRedisClient()
defer client.Close()
// WATCH-CAS 监测如改动则 EXEC 放弃
doFunc := func(tx *redis.Tx) error {
// MULTI
flag, _ := tx.Get("flag").Result()
val, _ := strconv.ParseInt(flag, 10, 0)
//pipe := tx.Pipeline()
//pipe.Set("flag", val+1, 0)
//pipe.Exec()
_, err := tx.Pipelined(func(pipe redis.Pipeliner) error {
pipe.Set("flag", val+1, 0)
return nil
})
// EXEC
return err
}
//client.Watch(doFunc, "flag1", "flag2", "flag3")
client.Watch(doFunc, "flag")
}
leveldb 也是一个 kv 数据库引擎,它的设计和代码都算的上非常优雅,由谷歌的工程师发明,可以很方便的内嵌到程序里,默认按照 key 的字典顺序来存储访问,而且自动压缩,key 和 value 都支持任意长度的字节数。首先安装 leveldb 的依赖包:
go get github.com/syndtr/goleveldb
要使用 leveldb 接口,首先也得获得 level.DB 对象,其内部维持了 session 会话,和 redis 访问不同的是,它的接口需要使用 []byte 类型:
func keyValue() {
db := session.GetLevelDB()
defer db.Close()
db.Put([]byte("1st"), []byte("1"), nil)
data, _ := db.Get([]byte("1st"), nil)
fmt.Println(string(data))
}
迭代的时候可以按照 key 的顺序访问,这是 leveldb 的特点:
func iterAll() {
db := session.GetLevelDB()
defer db.Close()
db.Put([]byte("3rd"), []byte("3"), nil)
db.Put([]byte("2nd"), []byte("2"), nil)
db.Put([]byte("1st"), []byte("1"), nil)
// 会按照 1st 2nd 3rd 的顺序输出
iter := db.NewIterator(nil, nil)
for iter.Next() {
key := iter.Key()
value := iter.Value()
fmt.Printf("%v %v\n", string(key), string(value))
}
iter.Release()
}
遍历的时候也支持范围 range 和步进 seek 操作:
func iterRange() {
db := session.GetLevelDB()
defer db.Close()
iter := db.NewIterator(&util.Range{Start: []byte("2nd"), Limit: []byte("3rd")}, nil)
for iter.Next() {
key := iter.Key()
value := iter.Value()
fmt.Printf("%v %v\n", string(key), string(value))
}
iter.Release()
fmt.Println("------")
}
func seek() {
db := session.GetLevelDB()
defer db.Close()
iter := db.NewIterator(nil, nil)
for ok := iter.Seek([]byte("2nd")); ok; ok = iter.Next() {
key := iter.Key()
value := iter.Value()
fmt.Printf("%v %v\n", string(key), string(value))
}
iter.Release()
fmt.Println("------")
}
相对于 redis、leveldb 的访问,mongodb 会稍显复杂,除了有相似的 mongo.Client 对象,还需要了解一下 bson 的数据类型定义,先看如何获取 mongo.Client 对象:
func GetMongoClient() *mongo.Client {
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
client, err := mongo.Connect(ctx, options.Client().ApplyURI("mongodb://localhost:27017"))
if err != nil {
panic(err)
}
return client
}
时间操作数据的时候常用的是 Database、 Collection、Cursor 3 个对象,可以随意切换数据库,下面是一个插入的例子:
func insert() {
client := session.GetMongoClient()
defer client.Disconnect(nil)
persons := client.Database("test").Collection("persons")
persons.InsertOne(nil, bson.M{
"username": "zhangsan",
"nickname": "张三",
"age": 20,
"create_time": time.Now(),
})
}
这里的 bson.M 的定义:
type M = primitive.M
// bson.M{"foo": "bar", "hello": "world", "pi": 3.14159}.
type M map[string]interface{}
可以见 bson.M 和 map[string]interface{} 一样,类似的 bson.A 是个数组:
// bson.A{"bar", "world", 3.14159, bson.D{{"qux", 12345}}}
type A []interface{}
查询的例子如下:
func findOne() {
client := session.GetMongoClient()
defer client.Disconnect(nil)
persons := client.Database("test").Collection("persons")
var result bson.M
persons.FindOne(nil, bson.D{}).Decode(&result)
fmt.Println(result)
}
这里的查询条件使用 bson.D 就不太好理解了,F12 进去看看定义:
// bson.D{{"foo", "bar"}, {"hello", "world"}, {"pi", 3.14159}}
type D = primitive.D
type D []E
type E = primitive.E
// E represents a BSON element for a D. It is usually used inside a D.
type E struct {
Key string
Value interface{}
}
原来 bson.D 是一个 key、value 对象的数组,所以查询 userame=zhangsan 要这么写:
persons.FindOne(nil, bson.D{{"username","zhangsan"}}).Decode(&result)
为什么不是直接弄成 bson.M 呢? 主要是因为查询条件是有顺序的,特别是 mongodb 的 pipeline,顺序不同过滤数据的结果不同,数组才能保证顺序,而 bson.M 不能。
对查询的结果使用 cursor 遍历,要得到遍历的错误和标准的 sql 库 Scan() 函数类似,需要使用 cur.Err() 获取:
func find() {
client := session.GetMongoClient()
defer client.Disconnect(nil)
persons := client.Database("test").Collection("persons")
cur, _ := persons.Find(nil, bson.D{})
for cur.Next(nil) {
var result bson.M
cur.Decode(&result)
fmt.Println(result)
}
// cur.Err()
}
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/23-access-nosql-db
24-解析命令行参数
我们在终端 shell 下输入命令的时候,往往会看到一个帮助信息,根据帮助信息得知该命令的基本用法,并且含有很多参数,本章就来实现类似的功能。
如何直接获取命令行的参数呢? 系统 os 包提供了 os.Args,它是一个 string 的数组:
func main() {
fmt.Println(os.Args)
}
输入命令行 go run main.go macos linux windows,将打印出如下的结果:
[/var/folders/jw/rpyqrcvd6jb5w9v2lq0pnnpw0000gn/T/go-build203870186/b001/exe/main macos linux windows]
可以看出,第一部分是命令本身,第二部分才是参数。
通常典型的一个命令的帮助信息有以下形式:
- cmd -h
- cmd --help
- cm -?
虽然 os.Args 能提供命令行的信息,但如果自行去解析这个参数,那就太复杂了。go 内置的包 flag 可以把这件事做好,flag 包对命令参数的类型做了定义:
- 布尔命令
- 字符串
- 数值
比如打印命令的帮助信息就是一个开关,如果命令行传递了 -h、--help、-? 等就认为是要查看命令的帮助信息,实现方式分为 2 步:
- 定义绑定命令参数的变量
- 调用 flag.Parse 解析
func main() {
flag.BoolVar(&help, "h", false, "show help")
flag.Parse()
}
flag.BoolVar 表示要绑定 h 命令参数到 help 变量上,第三个参数 false 表示该变量的默认值是 false,如果命令行没有这个参数,help=false,有了 help 变量就好办了,如果 help 为 true,就打印帮助信息,退出:
if help {
usage()
return
}
func usage() {
//
}
输入 go run main.go --help 看看显示:
24-parse-cmd-flags[master*] 🍎 go run main.go --help
Usage of /var/folders/jw/rpyqrcvd6jb5w9v2lq0pnnpw0000gn/T/go-build694631870/b001/exe/main:
-h show help
自动打印除了 -h 的帮助信息,再加一个绑定 --color 看看效果:
24-parse-cmd-flags[master*] 🍎 go run main.go --help
Usage of /var/folders/jw/rpyqrcvd6jb5w9v2lq0pnnpw0000gn/T/go-build632569444/b001/exe/main:
-color
apply color display
-h show help
这是因为默认打印的是 flag.Usage() 函数的结果,因为我们这里的 usage 函数什么都没干,如果需要替换掉 flag.Usage() 默认的帮助信息,可以简单的把 flag.Usage 函数地址换掉就行了:
flag.Usage = usage
flag.Parse()
if help {
return
}
运行 go run main.go --help 显示:
24-parse-cmd-flags[master*] 🍎 go run main.go --help
你好,这是自定义帮助信息
这样的帮助信息没有参数用法,可以使用 flag.PrintDefaults() 函数找回来,修改 usage 函数如下:
func usage() {
fmt.Fprintf(os.Stderr, "你好,这是自定义帮助信息\n")
flag.PrintDefaults()
}
现在运行 go run main.go --help 就完美了:
24-parse-cmd-flags[master*] 🍎 go run main.go --help
你好,这是自定义帮助信息
-color
apply color display
-h show help
同理,增加一个 hours 参数,并且具有默认是:
flag.IntVar(&hours, "hours", 24, "date time mode")
// ...
if hours == 24 {
fmt.Println("23:59:59")
} else {
fmt.Println("not 24 hours mode")
}
运行 go run main.go 和 go run main.go --hours=24、go run main.go --hours 24 都显示 23:59:59,其他的 hours 参数会则打印提示:
24-parse-cmd-flags[master*] 🍎 go run main.go --hours 12
not 24 hours mode
对于 flag.IntVar 这种指针定义形式,也可以用下面的写法:
var hours = flag.Int("hours", 24, "date time mode")
对 string 的绑定使用 flag.StringVar,相信你也会了。需要注意的参数形式是 -flag 形式支持 bool,-flag x 只支持非 bool,而 -flag 都支持。
如果想解析 --fruits "apple,orange,banana" 怎么做呢? 简单,用 StringVar 啊,没错,但是 StringVar 只能得到 fruits=apple,orange,banana,我希望直接解析成切片 fruits=[]string{"apple", "orange", "banana"} 怎么办? flag 提供了灵活性,可以使用 flag.Var 来自定义,不过这种自定义的类型必须实现 flag.Value 接口,它的要求是:
type Value interface {
String() string
Set(string) error
}
实现一个解析 fruits 参数的类型:
type sliceArg []string
// 构造函数, def 实现了默认值
func New(p *[]string, def []string) *sliceArg {
*p = def
return (*sliceArg)(p)
}
func (s *sliceArg) Set(val string) error {
*s = sliceArg(strings.Split(val, ","))
return nil
}
func (s *sliceArg) String() string { return strings.Join(*s, ",") }
用法:
flag.Var(New(&fruits, []string{"nothing"}), "fruits", "do you like sth")
//...
fmt.Println(fruits)
现在运行 go run main.go 显示 fruits 的值是 [nothing],而 go run main.go --fruits "apple,orange" 的值的还是 [apple orange],把 "apple,orange" 成功的解析到了 []string 切片类型。
24-parse-cmd-flags[master*] 🍎 go run main.go --fruits "apple,orange"
23:59:59
[apple orange]
24-parse-cmd-flags[master*] 🍎 go run main.go
23:59:59
[nothing]
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/24-parse-cmd-flags
25-打包编译信息的套路
go build 可以编译出二进制的可执行文件,因为 go 有交叉编译的特性,在 mac 上也可以编译出 linux 的可执行文件,比如:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go
- CGO_ENABLED=0 禁用 CGO 特性,该特性将在调用 C/C++ 部分学习
- GOOS 指明运行的目标系统,有 darwin、linux、freebsd、windows 等
- GOARCH 表示系统的CPU架构,386、amd64、arm 等
关于 GOOS 和 GOARCH 的值可以参考 https://gist.github.com/asukakenji/f15ba7e588ac42795f421b48b8aede63。
运行某些 go 程序的时候常常打印出如下的信息:
# ./main -version
version: v5.13.4
git hash: a8de74c76929d10dea7fe2c14fc098ef42f438c6
build time: 20201228-10:20:29
分别是版本号 version,应该是 git tag 的标签,git hash 仓库提交的 commit 的 SHA 码,build time 打包的时间,像这种嵌入到可执行文件的额外信息怎么在编译时生成呢? 按照上一章节的思路,使用 flag.Parse 处理 version 打印出三个字段的信息即可。
// meta/config/config.go
var (
Version = ""
GitHash = ""
BuildTime = ""
)
// main.go
var version bool
func main() {
flag.BoolVar(&version, "version", false, "print version info")
flag.Parse()
if version {
fmt.Printf("version:\t\t%s", Version)
fmt.Printf("git hash:\t\t%s", GitHash)
fmt.Printf("build time:\t\t%s", BuildTime)
}
}
好了,运行 go build main.go && ./main 后打印了三行空信息,解析 version 的工作已经完成,现在的关键是如何在 build 时获得这三个字段的信息,获取后通过修改 config.go 文件中的代码后再 build 即可。
在 bash 中获取的方法:
- version=
git tag | tail -n 1# 获取最后一个 tag 标签 - git_hash=
git rev-parse HEAD# 提交的 commit 码 - build_time=
date +%Y%m%d-%H:%M:%S# 当前的日期时间
可以通过 bash 脚本直接替换掉 config.go 中的字段值,不过 go build 提供了 --ldflags 编译参数,配合 -X 可以替换掉 config.go 中的字段值,为了编译方便统一为 build.sh 脚本:
#!/bin/bash
build() {
version=`git tag | tail -n 1`
git_hash=`git rev-parse HEAD`
build_time=`date +%Y%m%d-%H:%M:%S`
cmd="GOOS=darwin GOARCH=amd64 go build -o=./main -ldflags \"
-X '25-build-with-meta/meta/config.Version=$version' \
-X '25-build-with-meta/meta/config.GitHash=$git_hash' \
-X '25-build-with-meta/meta/config.BuiltTime=$build_time' \""
echo $cmd
eval $cmd
}
build
echo "build finish"
注意 25-build-with-meta/meta/config 是包名,它对应的文件是 meta/config/config.go,运行 chmod +x ./build.sh && ./build.sh 显示 build finish 编译完成:
# ./build.sh
GOOS=darwin GOARCH=amd64 go build -o=./main -ldflags " -X '25-build-with-meta/meta/config.Version=v1.0' -X '25-build-with-meta/meta/config.GitHash=415ca4116fdb354b121c59863d3509e34056f580' -X '25-build-with-meta/meta/config.BuildTime=20210120-10:41:57' "
build finish
运行 ./main -version 显示:
# ./main -version
version: v1.0
git hash: 415ca4116fdb354b121c59863d3509e34056f580
build time: 20210120-10:41:57
主要用法 -ldflags -X importpath.name=value,参考 https://golang.org/cmd/link/,使用此方法你可以为程序嵌入其他元信息。
-X importpath.name=value
Set the value of the string variable in importpath named name to value.
This is only effective if the variable is declared in the source code either uninitialized
or initialized to a constant string expression. -X will not work if the initializer makes
a function call or refers to other variables.
Note that before Go 1.5 this option took two separate arguments.
作为一个小作业,请你嵌入编译时的 go 的版本信息,运行 ./main -version 显示:
./main -version
version: v1.0
git hash: 2d432eac0876c7e33efe6ff32fbbb43ec44ad1c3
build time: 20210120-10:55:14
go version: go version go1.15.5 darwin/amd64
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/25-build-with-meta
26-常用编译指令参数
上一章节学习了 -ldflags -X 的用法,-lgflags 还有两个常用的参数:
- -w 去掉调试信息
- -s 去掉符号表
写一个什么都不干的 main.go 执行 go build -o=./main main.go && ls -lh main:
# go build -o=./main main.go && ls -lh main
-rwxr-xr-x 1 wangbo staff 1.2M 1 20 11:02 main
它的大小是 1.2M,执行 go build -o=./main -ldflags "-w -s" main.go && ls -lh main:
# go build -o=./main -ldflags "-w -s" main.go && ls -lh main
-rwxr-xr-x 1 wangbo staff 867K 1 20 11:05 main
其文件大小降低为 867K,如果需要对程序进行调试则需要保留调试信息和符号表,否则就去掉。
-x 显示编译连接的过程:
# go build -x main.go
WORK=/var/folders/jw/rpyqrcvd6jb5w9v2lq0pnnpw0000gn/T/go-build057203084
mkdir -p $WORK/b001/
cat >$WORK/b001/importcfg.link << 'EOF' # internal
packagefile command-line-arguments=/Users/wangbo/Library/Caches/go-build/80/80b6c11eb8d8ea82f95ff2929da9bcb38270614499babfd758b10f0aa574f257-d
packagefile runtime=/usr/local/go/pkg/darwin_amd64/runtime.a
packagefile internal/bytealg=/usr/local/go/pkg/darwin_amd64/internal/bytealg.a
packagefile internal/cpu=/usr/local/go/pkg/darwin_amd64/internal/cpu.a
packagefile runtime/internal/atomic=/usr/local/go/pkg/darwin_amd64/runtime/internal/atomic.a
packagefile runtime/internal/math=/usr/local/go/pkg/darwin_amd64/runtime/internal/math.a
packagefile runtime/internal/sys=/usr/local/go/pkg/darwin_amd64/runtime/internal/sys.a
EOF
mkdir -p $WORK/b001/exe/
cd .
/usr/local/go/pkg/tool/darwin_amd64/link -o $WORK/b001/exe/a.out -importcfg $WORK/b001/importcfg.link -buildmode=exe -buildid=VO2fnCWApwZeNGuGyqj0/FXrj_zykxVHTmNlCur6C/VM6QVuSfezjKBeyD8n26/VO2fnCWApwZeNGuGyqj0 -extld=clang /Users/wangbo/Library/Caches/go-build/80/80b6c11eb8d8ea82f95ff2929da9bcb38270614499babfd758b10f0aa574f257-d
/usr/local/go/pkg/tool/darwin_amd64/buildid -w $WORK/b001/exe/a.out # internal
mv $WORK/b001/exe/a.out main
rm -r $WORK/b001/
-a 强制重新构建,默认为了增加编译速度,没有改动的部分不会重新编译,-a 参数则忽略这些编译好的部分,全部重新编译,所以 -a 会比较慢。
系统内置的 // +build !linux 在非 linux 下包含该文件,而 // +build linux,amd64 darwin 在 linux amd64 和 macos 下包含该文件,自定义的 tag 可以通过 --tags 参数实现,通过 -tags 构建带特殊的版本,比如文件头 // +build sessredis 配合 -tags "sessredis" 则文件会包含进编译,表明使用 redis 实现 session 的版本,而 // +build !sessredis 的文件会排除,表明使用默认的 cookie 来实现 session 的版本,反之亦然。

go test -race 和 go build -race 参数可以检测竞争状态,静态分析程序是不是有隐含的竞争问题,可能会出 bug 的读写操作。go run -race main.go 运行下面的程序会收到 DATA RACE 报警:
package main
var sum int
func main() {
go add()
go add()
}
func add() {
sum++
}
-gcflags="-N -I" 禁止编译优化和内敛优化,对单独的函数可以标注 //go:noline 来设定不要内敛优化,//go:nosplit 跳过栈溢出检查,// go:noescape 禁止逃逸分析,//go:norace 跳过静态检查,在后面的反编译章节会用到这几个编译设定。
XX_$GOOS_$GOARCH.go 特定的平台和架构下包含该文件,比如 task_darwin_amd64.go、task_linux_amd64.go 等。

本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/26-compile-switch
27-调用 C 语言函数
本地的 go build 编译的时候默认是启用 C/C++ 支持的,对应的编译开关是 CGO_ENABLED,交叉构建需要使用 CGO_ENABLED=1,最简单的 CGO 程序如下:
package main
// cgo enabled default
import "C"
func main() {}
没错,import "C" 可以导入 C 的类型,表明需要调用 C 库,CGO 的特色之一就可以直接在 go 文件里编写 C 语言的模块,编写的 C 代码部分必须在 import "C" 之上,import 语句之前不能有空行,下面的例子调用了 C 的 puts 函数:
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hi, cgo lib"))
}
C.puts 调用 puts 函数,它的原型是:
int puts(const char *str)
C.CString 是把 go 的 string 转换到 C 的 *char,不过这个转换不会自动释放内存,需用调用 free 释放,下面是 CString 的签名:
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
和 C.CString 相似是的 C.CBytes([]byte) unsafe.Pointer 函数用于转换 go 的 []byte 切片,也需要自行 free,上面的例子完整的代码是:
//#include <stdio.h>
//#include <stdlib.h>
import "C"
import "unsafe"
func main() {
cstr := C.CString("hi, cgo lib")
C.puts(cstr)
C.free(unsafe.Pointer(cstr))
}
unsafe.Pointer 获得指针的值,传递给 C 的 free 函数,free 函数 stdlib.h 中,所以需要包含。反过来,如果把 C 的 *char 换换成 go 的 string,可以使用 C.GoString 函数,类似的也有 func C.GoBytes(unsafe.Pointer, C.int) []byte。
str := C.GoString(cstr)
fmt.Println(str)
CGO 会自动构建当前目录下的 C 源文件,所以把可以把上面 C 的部分独立出来,这样可以实现 C 的模块化:
// say.h
void Say(const char* s);
// say.c
#include "say.h"
#include <stdio.h>
void Say(const char* s) {
puts(s);
}
// main.go
package main
//#include "say.h"
import "C"
func main() {
C.Say(C.CString("hi, cgo"))
}
请注意,不能使用 go run main.go 来运行了,要使用 go run . 来运行,不仅 go 可以调用 C 模块的函数,C 的函数也可以由 go 来实现:
// say.h
void Say(char* s);
// say.go
package main
import "C"
import "fmt"
//export Say
func Say(s *C.char) {
fmt.Print(C.GoString(s))
}
// main.go
package main
//#include <say.h>
import "C"
func main() {
C.Say(C.CString("hi, cgo"))
}
say.h 头文件申明了 Say 函数的签名,但是它使用 say.go 来实现的函数体,注意两点:
- // export Say 是必须的,表示把 go 的函数和导出为 C 的函数
- 和 C 模块化一样,也得使用 go run . 运行否则链接失败

当然也可以把这三个文件合并到一个 go 文件里,又可以使用 go run main.go 运行了。
package main
//void Say(char* s);
import "C"
import (
"fmt"
)
func main() {
C.Say(C.CString("hi, cgo"))
}
//export Say
func Say(s *C.char) {
fmt.Println(C.GoString(s))
}
CGO 看似实现了 C 和 Go 的直接调用,实施上并非如此,当发现 import "C" 时,编译会产生 C 和 Go 之间的中介代码,执行 go tool cgo main.go 可以查看到中间代码:
27-call-c-module[master*] 🍎 go tool cgo main.go
27-call-c-module[master*] 🍎 tree _obj
_obj
├── _cgo_export.c
├── _cgo_export.h
├── _cgo_flags
├── _cgo_gotypes.go
├── _cgo_main.c
├── main.cgo1.go
└── main.cgo2.c
CGO 还支持 # cgo CFLAGS LDFLAGS 设定编译连接参数,更多 CGO 的知识参考官网:
- https://golang.org/cmd/cgo
- https://blog.golang.org/cgo
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/27-call-c-module
28-调用 C++ 类函数
CGO 不能直接支持 C++,只能靠 C 来嫁接,所以也不能支持 C++特有的类型,比如引用参数、对象类。如果把上一章节的 Say 函数使用 C++ 实现,其实和 C、C++ 配合没什么区别,主要使用 extern "C" 让 cpp 生成的函数符合 C 的调用规范,代码如下:
// say.h
void Say(const char* s);
// say.cpp
#include <iostream>
extern "C" {
#include "say.h"
}
void Say(const char* s) {
std::cout << s;
}
// main.go
package main
//#include "say.h"
import "C"
func main() {
C.Say(C.CString("hi, cgo"))
}
但是使用 C++类就不同了,先说结论,使用 C++ 类的步骤:
用纯 C 来包装 C++ 的类对象行为
将包装的 C 函数映射到 Go 的函数
调用 Go 的包装函数
下面举例,首先写一个 Person 的 C++ 类(使用 struct),有 2 个属性(name、age)和一个 方法(Say):
//person.h
#define _GLIBCXX_USE_CXX11_ABI 0 // 禁用 C++ 11 的新类
#include <iostream>
#include <string>
using namespace std;
struct Person
{
private:
string name;
int age;
public:
Person(string name, int age);
void Say();
};
Person::Person(string name, int age)
{
this->name = name;
this->age = age;
}
void Person::Say()
{
cout << "name: " << this->name << ", age: " << this->age;
}
第二步,编写包装的 C 函数,定义了 C 的类型 Person_T,把创建对象、调用 Say、释放对象都定义了 C 风格的函数:
// person_cgo.h
typedef struct Person_T Person_T;
Person_T* NewPerson(const char* name, int age);
void PersonSay(Person_T *person);
void DeletePerson(Person_T* person);
第三步,在 cpp 文件里使实现 C 的函数,注意新的类型 Person_T 继承 C++ 类型 Person:
// person_cgo.cpp
#include "person.h"
extern "C"
{
#include "person_cgo.h"
}
struct Person_T : Person
{
Person_T(const char *name, int age) : Person(name, age) {}
~Person_T() {}
};
Person_T *NewPerson(const char *name, int age)
{
return new Person_T(name, age);
}
void PersonSay(Person_T *person)
{
person->Say();
}
void DeletePerson(Person_T *person)
{
delete person;
}
第三步,就是使用 import "C" 来调用了,定义了 CGO_NewPerson、CGO_PersonSay、CGO_DeletePerson 来映射:
// main.go
package main
//#include "person_cgo.h"
import "C"
type CGO_Person_T = C.Person_T
func CGO_NewPerson(name string, age int) *CGO_Person_T {
return C.NewPerson(C.CString(name), C.int(age))
}
func CGO_PersonSay(person *CGO_Person_T) {
C.PersonSay(person)
}
func CGO_DeletePerson(person *CGO_Person_T) {
C.DeletePerson(person)
}
func main() {
person := CGO_NewPerson("zhangsan", 20)
CGO_PersonSay(person)
CGO_DeletePerson(person)
}
执行 go run . 显示:
callcppclass[master*] 🍎 go run .
name: zhangsan, age: 20
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/28-call-cplusplus-module
29-反汇编和内存结构
使用 go tool compile -S main.go 可以显示出 go 汇编的代码(或 go build -gcflags -S main.go),go 汇编基于 plan 9,和系统底层的汇编代码有所区别, 但是做到了跨平台汇编与具体的系统架构无关。很多人都吐槽为什么是 plan 9? plan 9 是 1980 年代中期的一个分布式操作系统,被称为贝尔实验室 9 号项目,作为 UNIX 的后继,现在任然被爱好者研究和使用。
main.go 的源代码和对应的 go 汇编代码:
package main
import (
"runtime"
)
func main() {
println(runtime.GOOS)
}

先忽略掉 PCDATA 和 FUNCDATA,它们是给 GC 垃圾收集器提供附加信息的指令。执行 go build 把它编译成可执行文件,用 go tool objdump 就能看到生成的二进制文件的汇编代码,我目前的系统是 darwin intel i7:
# go build -o main main.go
# go tool objdump -s main.main main
二进制汇编代码的结果:

官网有一个汇编入门的教程 https://golang.org/doc/asm, 注意 go 汇编是基于 package 的,从最简单的开始,首先看看如何定义包的导出变量:
// id.go
package vardef
var ID= 9927
// str.go
package vardef
var Str = "hello"
因为不涉及到任何函数调用,这两个文件产生的伪汇编代码比较简单:
// id.go
vardef[master*] 🍎 go tool compile -S id.go
go.cuinfo.packagename. SDWARFINFO dupok size=0
0x0000 76 61 72 64 65 66 vardef
"".ID SNOPTRDATA size=8
0x0000 c7 26 00 00 00 00 00 00 .&......
// str.go
vardef[master*] 🍎 go tool compile -S str.go
go.cuinfo.packagename. SDWARFINFO dupok size=0
0x0000 76 61 72 64 65 66 vardef
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
"".Str SDATA size=16
0x0000 00 00 00 00 00 00 00 00 05 00 00 00 00 00 00 00 ................
rel 0+8 t=1 go.string."hello"+0
第一个程序 id.go 定义了一个整数,第二个 str.go 定义了一个字符串。在 go 的 asm 文档中找到数据的定义结构:
DATA symbol+offset(SB)/width, value
GLOBL symbol(SB), width
GLOBL symbol(SB), RODATA, width // 只读
symbol 是标识符,.symbol 是当前包,比如 .ID、.Str
offset 是初始地址的偏移量
value 是值, width 是内存宽度,width 必须是 1、2、4、8、16 等
除了 DATA,还有 TEXT 定义函数、GLOBL 导出全局变量,SRODATA 表示数据在内存只读,因为 go 字符串本质是一种只读的引用类型,dupok 表示只有一份,它完整的引用符号是 go.string."hello",如果再出现对 hello 的引用,就可以连接 go.string."hello" 这个符号上,后面的 .Str 就引用了这个 hello 符号,而且 "".Str 的 size=16,表示占用 16 个字节,为什么呢? 因为前面章节讲过 StringHeader 的定义是:
type reflect.StringHeader struct {
Data uintptr
Len int
}
Data 字段是指向 go.string."hello" 的指针,这个指针大小是 8 个字节,Len 表示有效数据的长度,也占 8 个字节,跳过引用地址的 0x0000 8 个字节后是 05,因为 hello 的长度是 5 个字节。相对于 SDATA,定义 "".ID 的 SNOPTRDATA 表示不包含指针。
在继续函数之前,有必要先了解一下 plan 9 汇编指令和寄存器。plan 9 没有 intel 的 push、pop 指令,依靠 SP 的加减操作来操作函数栈帧,go 的伪寄存器、通用寄存器、指令和操作数基本的规则:
伪寄存器 SP 局部变量的底部(栈方向高大到低,也是当前栈的 BP 基地址,往栈底方向是调用者 ret 返回地址),SP - 8 是倒数第一个 int 本地变量,SP -16 倒数第二个(注意栈的增长方向是高地址向低地址扩张),SP 增长方向就是返回地址和调用者参数了
伪寄存器 SP 只有在手写会编是用到,它指向当前函数栈的栈顶位置,手写汇编使用伪寄存器前面要带 symbol,否则是调用硬件寄存器,反编译后的 SP 都是硬件 SP,无论前面带不带 symbol,要特别注意
伪寄存器 FP 标识函数参数、返回值,直接 FP + 0 是第一个调用参数,FP +8 第二个调用参数
PC 就是 x86 的 IP 寄存器,EB 依然是基址寄存器,现代编译器中 EB 不是必须的但对调试有帮助
伪寄存器 SB 全局静态基地址,用来申明函数和全局变量
通用寄存器 rax、rbx、rcx 等,操作的时候 r 可以不写,和 Intel X86-64 不一样 (看第10条)
常数使用 $num 表示,可以直接使用 $0x 表示16 进制数,可以是用-表示负数
操作数的方向和 intel X86-64 是相反的,JMP 跳转同一函数内可以使用 label,会被转换成相对跳转
和 Intel x86-64 一样,(Reg) 引用寄存器的值所对应内存中的数据,没有内存 to 内存的指令,必须通过寄存器中转
指令决定操作数尺寸 XXXB = 1 XXXW = 2 XXXD = 4 XXXQ = 8,而 Intel 由操作的寄存器决定 AL/AH = 1、AX = 2、EAX = 4、RAX = 8

汇编操作指令的样例:
SUBQ $0x18, SP // 分配函数栈,操作数 8 个字节
ADDQ $0x18, SP // 清除函数栈,操作数 8 个字节
MOVB $1, DI // 拷贝 1个字节
MOVW $0x10, BX // 拷贝 2 个字节
MOVL $1, DX // 拷贝 4 个字节
MOVQ $-10, AX // 拷贝 8 个字节
ADDQ AX, BX // BX = BX + AX 存 BX
SUBQ AX, BX // BX = BX - AX 存 BX
IMULQ AX, BX // BX = BX * AX 存 BX
MOVQ AX, BX // BX = AX 将 AX 中的值赋给 BX
MOVQ (AX), BX // BX = *AX 加载 AX 中指向内存地址的值给 BX
MOVQ 16(AX), BX // BX = *(AX + 16) 偏移 16 个字节后地址中的值
编写一个加法的函数,go tool compile -S 结果如下:
// func.go
package funcasm
func add(a, b int) int {
return a + b
}
"".add STEXT nosplit size=19 args=0x18 locals=0x0
0x0000 00000 (func.go:3) TEXT "".add(SB), NOSPLIT|ABIInternal, $0-24
...
0x0000 00000 (func.go:4) MOVQ "".b+16(SP), AX
0x0005 00005 (func.go:4) MOVQ "".a+8(SP), CX
0x000a 00010 (func.go:4) ADDQ CX, AX
0x000d 00013 (func.go:4) MOVQ AX, "".~r2+24(SP)
0x0012 00018 (func.go:4) RET
SB 是程序地址空间开始的基地址,引用函数的输入参数表示形式 "".a+8(SP),"".b+16(SP),因为硬件 SP 指向函数栈栈顶地址。

$0-24 表示函数栈帧大小是 0,参数和返回值一共需要 24 个字节(3 个 int),~r2+24(SP) 是返回值的地址, RET 清除函数栈,弹出栈顶的返回地址到 IP 寄存器,从调用 add 的下一行开始执行。另外 NOSPLIT 的意思不插入检查栈扩张的指令(因为栈帧大小是 0 没必要检查),它对应 go 的编译指示 //go:nosplit。栈调用的一般性结构如下:

修改一下 func.go,创建一个局部变量,观察栈帧的大小变化:
// func2.go
package main
func add2(a, b int) int {
times := 2
println(times)
return (a - b) * times
}
// func2.o
"".add2 STEXT size=103 args=0x18 locals=0x10
0x0000 00000 (func2.go:3) TEXT "".add2(SB), ABIInternal, $16-24
0x0000 00000 (func2.go:3) MOVQ (TLS), CX // * thread local storage
0x0009 00009 (func2.go:3) CMPQ SP, 16(CX) // *
0x000d 00013 (func2.go:3) PCDATA $0, $-2
0x000d 00013 (func2.go:3) JLS 96 // *
0x000f 00015 (func2.go:3) PCDATA $0, $-1
0x000f 00015 (func2.go:3) SUBQ $16, SP // # 栈空间
0x0013 00019 (func2.go:3) MOVQ BP, 8(SP) // # 老的基址(保存 BP 寄存器的值到内存地址 8(SP))
0x0018 00024 (func2.go:3) LEAQ 8(SP), BP // # 新的基址(拷贝 8(SP) 的内存引用地址值到 BP)
...
0x001d 00029 (func2.go:5) NOP
0x0020 00032 (func2.go:5) CALL runtime.printlock(SB)
0x0025 00037 (func2.go:5) MOVQ $2, (SP)
0x002d 00045 (func2.go:5) CALL runtime.printint(SB)
0x0032 00050 (func2.go:5) CALL runtime.printnl(SB)
0x0037 00055 (func2.go:5) CALL runtime.printunlock(SB)
0x003c 00060 (func2.go:6) MOVQ "".a+24(SP), AX
0x0041 00065 (func2.go:6) MOVQ "".b+32(SP), CX
0x0046 00070 (func2.go:6) SUBQ CX, AX
0x0049 00073 (func2.go:6) SHLQ $1, AX // * 左移
0x004c 00076 (func2.go:6) MOVQ AX, "".~r2+40(SP)
0x0051 00081 (func2.go:6) MOVQ 8(SP), BP
0x0056 00086 (func2.go:6) ADDQ $16, SP
0x005a 00090 (func2.go:6) RET
0x005b 00091 (func2.go:6) NOP
0x005b 00091 (func2.go:3) PCDATA $1, $-1
0x005b 00091 (func2.go:3) PCDATA $0, $-2
0x005b 00091 (func2.go:3) NOP
0x0060 00096 (func2.go:3) CALL runtime.morestack_noctxt(SB) // * 扩容
0x0065 00101 (func2.go:3) PCDATA $0, $-1
0x0065 00101 (func2.go:3) JMP 0
包含一个局部变量 times,add 函数的栈帧大小是 16 字节。注意 // * 标记的是编译器插入的用于检查栈空间的代码,add2 和 add 不同的还有
标记的代码,因为 add2 还要调用 println 函数,在 println 函数返回的时候还需要恢复调用 add 的时候的 BP
基地址,所以需要保存老的 BP 地址,参数和返回值依然 24 个字节,注意 LEAQ 指令是引用寄存器指向的内存地址,不是加载它指向的值(理解为 & 取地址符)。

手写汇编代码的时候,不需要考虑 CALL 和 RET 指令对 PC 寄存器的操作影响,也不需要考虑 PC 寄存器插入的 8 字节返回地址占用的栈空间,仿造汇编的代码,写一个 add.s 汇编模块:
// add.s
#include "textflag.h"
TEXT ·add(SB), NOSPLIT, $0-24
MOVQ b+16(SP), AX // MOVQ b+8(FP), AX
MOVQ a+8(SP), BX // MOVQ a+0(FP), BX
ADDQ BX, AX
MOVQ AX, ret + 24(SP) // MOVQ AX, ret + 16(FP)
RET
// main.go
package main
func add(a, b int) int
func main() {
println(add(1, 2))
}
在个例子的栈帧为 0 比较特殊,也无本地局部变量和调用其他函数,不需要保存 BP 基地址,只需要跨过返回地址的 8 字节就行了。

当然用 FP 显得更加直观一些,输入 go run . 运行显示:
callasmfunc[master*] 🍎 go run .
3
编写一个返回多个值的函数:
package main
//go:noinline
func swap(a, b int) (int, int) {
return b+1, a+1
}
func main() {
_ = swap(0, 1)
}
//go:noinline 表示不要内联函数,swap 函数的汇编代码:
"".swap STEXT nosplit size=27 args=0x20 locals=0x0
0x0000 00000 (main.go:4) TEXT "".swap(SB), NOSPLIT|ABIInternal, $0-32
...
0x0000 00000 (main.go:5) MOVQ "".b+16(SP), AX
0x0005 00005 (main.go:5) INCQ AX
0x0008 00008 (main.go:5) MOVQ AX, "".~r2+24(SP) // *
0x000d 00013 (main.go:5) MOVQ "".a+8(SP), AX
0x0012 00018 (main.go:5) INCQ AX
0x0015 00021 (main.go:5) MOVQ AX, "".~r3+32(SP) // *
0x001a 00026 (main.go:5) RET
参数 2 个和返回值 2 个,共 $0-32 栈帧大小为 0,返回值的方式直接操作 SP 偏移实现,main 调用 swap 函数:

"".main STEXT size=71 args=0x0 locals=0x28
0x0000 00000 (main.go:8) TEXT "".main(SB), ABIInternal, $40-0
...
0x000f 00015 (main.go:8) SUBQ $40, SP
0x0013 00019 (main.go:8) MOVQ BP, 32(SP) // 基址
0x0018 00024 (main.go:8) LEAQ 32(SP), BP
...
0x001d 00029 (main.go:9) MOVQ $0, (SP) // *
0x0025 00037 (main.go:9) MOVQ $1, 8(SP) // *
0x002e 00046 (main.go:9) PCDATA $1, $0
0x002e 00046 (main.go:9) CALL "".swap(SB)
0x0033 00051 (main.go:10) MOVQ 32(SP), BP // *
0x0038 00056 (main.go:10) ADDQ $40, SP // *
0x003c 00060 (main.go:10) RET
...
编写使用结构体的代码,看看 new(Person) 和 &Person{} 有无区别:
package main
type Person struct{}
func main() {
// var p *Person = &Person{}
p := &Person{}
println(p)
}
核心的汇编代码是:
0x0020 00032 (main.go:8) CALL runtime.printlock(SB)
0x0025 00037 (main.go:8) LEAQ ""..autotmp_2+8(SP), AX
0x002a 00042 (main.go:8) MOVQ AX, (SP)
0x002e 00046 (main.go:8) CALL runtime.printpointer(SB)
0x0033 00051 (main.go:8) CALL runtime.printnl(SB)
0x0038 00056 (main.go:8) CALL runtime.printunlock(SB)
0x003d 00061 (main.go:9) MOVQ 8(SP), BP
0x0042 00066 (main.go:9) ADDQ $16, SP
0x0046 00070 (main.go:9) RET
如果使用 p := new(Person) 核心汇编代码是:
0x0020 00032 (main.go:9) CALL runtime.printlock(SB)
0x0025 00037 (main.go:9) LEAQ ""..autotmp_1+8(SP), AX
0x002a 00042 (main.go:9) MOVQ AX, (SP)
0x002e 00046 (main.go:9) CALL runtime.printpointer(SB)
0x0033 00051 (main.go:9) CALL runtime.printnl(SB)
0x0038 00056 (main.go:9) CALL runtime.printunlock(SB)
0x003d 00061 (main.go:10) MOVQ 8(SP), BP
0x0042 00066 (main.go:10) ADDQ $16, SP
0x0046 00070 (main.go:10) RET
可见 new(Person) 和 &Person{} 没有性能上的区别,打印结构体地址的汇编:
0x0020 00032 (main.go:5) CALL runtime.printlock(SB)
0x0025 00037 (main.go:5) LEAQ ""..autotmp_2+8(SP), AX
0x002a 00042 (main.go:5) MOVQ AX, (SP)
0x002e 00046 (main.go:5) CALL runtime.printpointer(SB)
0x0033 00051 (main.go:5) CALL runtime.printnl(SB)
0x0038 00056 (main.go:5) CALL runtime.printunlock(SB)
0x003d 00061 (main.go:6) MOVQ 8(SP), BP
0x0042 00066 (main.go:6) ADDQ $16, SP
0x0046 00070 (main.go:6) RET
前面章节测试过,空结构体不占用内存,编译后是一个固定的内存地址,在汇编级别看看:
0x001d 00029 (main.go:7) XORPS X0, X0 // 清空 X0 寄存器
0x0020 00032 (main.go:7) MOVUPS X0, ""..autotmp_15+64(SP) // 初始化栈上临时空间
0x0025 00037 (main.go:7) LEAQ type.struct {}(SB), AX
0x002c 00044 (main.go:7) MOVQ AX, ""..autotmp_15+64(SP)
0x0031 00049 (main.go:7) LEAQ runtime.zerobase(SB), AX
0x0038 00056 (main.go:7) MOVQ AX, ""..autotmp_15+72(SP)
runtime.zerobase(SB) 就是空结构体的固定内存地址。嵌套结构体参数如何传递呢? 测试代码:
type Rank struct {
Level int
}
type Address struct {
Rank
StreetNo int
}
//go:noinline
func printAddr(addr Address) {
println(addr.Level)
println(addr.StreetNo)
}
func main() {
printAddr(Address{Rank: Rank{Level: 1}, StreetNo: 1})
}
可见被嵌套的结构体也按照字段传递,和直接把字段写在一个结构体里没有区别:
"".printAddr STEXT size=110 args=0x10 locals=0x10
0x0000 00000 (main.go:12) TEXT "".printAddr(SB), ABIInternal, $16-16
...
0x0020 00032 (main.go:13) CALL runtime.printlock(SB)
0x0025 00037 (main.go:13) MOVQ "".addr+24(SP), AX
0x002a 00042 (main.go:13) MOVQ AX, (SP)
0x002e 00046 (main.go:13) CALL runtime.printint(SB)
0x0033 00051 (main.go:13) CALL runtime.printnl(SB)
0x0038 00056 (main.go:13) CALL runtime.printunlock(SB)
0x003d 00061 (main.go:13) NOP
0x0040 00064 (main.go:14) CALL runtime.printlock(SB)
0x0045 00069 (main.go:14) MOVQ "".addr+32(SP), AX
0x004a 00074 (main.go:14) MOVQ AX, (SP)
0x004e 00078 (main.go:14) CALL runtime.printint(SB)
0x0053 00083 (main.go:14) CALL runtime.printnl(SB)
0x0058 00088 (main.go:14) CALL runtime.printunlock(SB)
0x005d 00093 (main.go:15) MOVQ 8(SP), BP
0x0062 00098 (main.go:15) ADDQ $16, SP
0x0066 00102 (main.go:15) RET
"".main STEXT size=71 args=0x0 locals=0x18
0x0000 00000 (main.go:18) TEXT "".main(SB), ABIInternal, $24-0
...
0x001d 00029 (main.go:19) MOVQ $1, (SP)
0x0025 00037 (main.go:19) MOVQ $1, 8(SP)
0x002e 00046 (main.go:19) PCDATA $1, $0
0x002e 00046 (main.go:19) CALL "".printAddr(SB)
0x0033 00051 (main.go:20) MOVQ 16(SP), BP
0x0038 00056 (main.go:20) ADDQ $24, SP
0x003c 00060 (main.go:20) RET
传递数组参数,为了函数体简单,只打印了第一个元素:
func printArray(data [3]int) {
print(data[0])
}
"".printArray STEXT size=80 args=0x18 locals=0x18
0x0000 00000 (array.go:3) TEXT "".printArray(SB), ABIInternal, $24-24
...
0x001d 00029 (array.go:4) MOVQ "".data+32(SP), AX // * 加上 ret 和 bp 的 16,定位第 0 个元素
0x0022 00034 (array.go:4) MOVQ AX, ""..autotmp_2+8(SP)
0x0027 00039 (array.go:4) PCDATA $1, $0
0x0027 00039 (array.go:4) CALL runtime.printlock(SB)
0x002c 00044 (array.go:4) MOVQ ""..autotmp_2+8(SP), AX
0x0031 00049 (array.go:4) MOVQ AX, (SP)
0x0035 00053 (array.go:4) CALL runtime.printint(SB)
0x003a 00058 (array.go:4) CALL runtime.printunlock(SB)
0x003f 00063 (array.go:5) MOVQ 16(SP), BP
0x0044 00068 (array.go:5) ADDQ $24, SP
0x0048 00072 (array.go:5) RET
...
0x004e 00078 (array.go:3) JMP 0
"".main STEXT size=77 args=0x0 locals=0x20
0x0000 00000 (array.go:8) TEXT "".main(SB), ABIInternal, $32-0
...
0x001d 00029 (array.go:9) MOVQ $1, (SP)
0x0025 00037 (array.go:9) MOVQ $2, 8(SP)
0x002e 00046 (array.go:9) MOVQ $3, 16(SP)
0x0037 00055 (array.go:9) PCDATA $1, $0
0x0037 00055 (array.go:9) CALL "".printArray(SB)
...
把数组的每个值从右到左都放到栈上(类似 N 个参数),切片和数组的区别是很大的,看看 slice 切片如何传递的:
package main
import "fmt"
//go:noinline
func printSlice(slice []int) {
fmt.Println(slice)
}
func main() {
printSlice([]int{1, 2, 3})
}
对应的 main 的汇编代码:
"".main STEXT size=118 args=0x0 locals=0x20
0x0000 00000 (main.go:10) TEXT "".main(SB), ABIInternal, $32-0
...
0x000f 00015 (main.go:10) SUBQ $32, SP
0x0013 00019 (main.go:10) MOVQ BP, 24(SP)
0x0018 00024 (main.go:10) LEAQ 24(SP), BP
...
0x001d 00029 (main.go:11) LEAQ type.[3]int(SB), AX
0x0024 00036 (main.go:11) MOVQ AX, (SP)
0x0028 00040 (main.go:11) PCDATA $1, $0
0x0028 00040 (main.go:11) CALL runtime.newobject(SB)
0x002d 00045 (main.go:11) MOVQ 8(SP), AX
0x0032 00050 (main.go:11) MOVQ $1, (AX) // 元素1 8(SP)
0x0039 00057 (main.go:11) MOVQ $2, 8(AX) // 元素2 16(SP)
0x0041 00065 (main.go:11) MOVQ $3, 16(AX) // 元素3 24(SP)
0x0049 00073 (main.go:11) MOVQ AX, (SP) // Data 地址
0x004d 00077 (main.go:11) MOVQ $3, 8(SP) // Len 大小
0x0056 00086 (main.go:11) MOVQ $3, 16(SP) // Cap 大小
0x005f 00095 (main.go:11) NOP
0x0060 00096 (main.go:11) CALL "".printSlice(SB)
0x0065 00101 (main.go:12) MOVQ 24(SP), BP
0x006a 00106 (main.go:12) ADDQ $32, SP
0x006e 00110 (main.go:12) RET
对应 reflect.SliceHedaer 和 runtime.newobject(SB) 的定义:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
func newobject(typ *_type) unsafe.Pointer {
return mallocgc(typ.size, typ, true)
}
初始化 slice 有三个元素值指向堆中的地址,调用的时候也是传入三个值,实际的值通过 *AX 指向的内存区域 (AX) 来操作,$3 是因为切片的 len 和 cap 都是 3,切片的三个成员字段都被复制,这段代码不多,但是栈变化比较复杂:

被调用参数的处理:
"".printSlice STEXT size=175 args=0x18 locals=0x58
0x0000 00000 (main.go:6) TEXT "".printSlice(SB), ABIInternal, $88-24
0x0000 00000 (main.go:6) MOVQ (TLS), CX
0x0009 00009 (main.go:6) CMPQ SP, 16(CX)
0x000d 00013 (main.go:6) PCDATA $0, $-2
0x000d 00013 (main.go:6) JLS 165
0x0013 00019 (main.go:6) PCDATA $0, $-1
0x0013 00019 (main.go:6) SUBQ $88, SP
0x0017 00023 (main.go:6) MOVQ BP, 80(SP) // 基址
0x001c 00028 (main.go:6) LEAQ 80(SP), BP
...
0x0021 00033 (main.go:7) MOVQ "".slice+96(SP), AX // *
0x0026 00038 (main.go:7) MOVQ AX, (SP)
0x002a 00042 (main.go:7) MOVQ "".slice+104(SP), AX // *
0x002f 00047 (main.go:7) MOVQ AX, 8(SP)
0x0034 00052 (main.go:7) MOVQ "".slice+112(SP), AX // *
0x0039 00057 (main.go:7) MOVQ AX, 16(SP)
0x003e 00062 (main.go:7) PCDATA $1, $1
0x003e 00062 (main.go:7) NOP
0x0040 00064 (main.go:7) CALL runtime.convTslice(SB) // *
0x0045 00069 (main.go:7) MOVQ 24(SP), AX // *
0x004a 00074 (main.go:7) XORPS X0, X0
0x004d 00077 (main.go:7) MOVUPS X0, ""..autotmp_13+64(SP)
0x0052 00082 (main.go:7) LEAQ type.[]int(SB), CX
0x0059 00089 (main.go:7) MOVQ CX, ""..autotmp_13+64(SP)
0x005e 00094 (main.go:7) MOVQ AX, ""..autotmp_13+72(SP)
注意 runtime.convTslice 把普通类型转换成切片结构:
// src/cmd/compile/internal/gc/builtin/runtime.go
func convTslice(val any) unsafe.Pointer
// src/runtime/iface.go
func convTslice(val []byte) (x unsafe.Pointer) {
if (*slice)(unsafe.Pointer(&val)).array == nil {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(unsafe.Sizeof(val), sliceType, true)
*(*[]byte)(x) = val
}
return
}
// sliceType
sliceType *_type = efaceOf(&sliceEface)._type
func efaceOf(ep *interface{}) *eface {
return (*eface)(unsafe.Pointer(ep))
}
// eface
type eface struct {
_type *_type
data unsafe.Pointer
}
最后看看 defer 插入的代码:
package main
func f() int {
i := 0
defer func(val int) {
val++
println(val)
}(i)
return i
}
汇编后调用 runtime.deferreturn(SB):
"".f STEXT size=144 args=0x8 locals=0x28
0x0029 00041 (defer.go:3) MOVB $0, ""..autotmp_3+15(SP)
0x002e 00046 (defer.go:3) MOVQ $0, "".~r0+48(SP)
0x0037 00055 (defer.go:6) LEAQ "".f.func1·f(SB), AX // *
0x003e 00062 (defer.go:6) MOVQ AX, ""..autotmp_4+24(SP)
0x0043 00067 (defer.go:6) MOVQ $0, ""..autotmp_5+16(SP)
0x004c 00076 (defer.go:6) MOVB $1, ""..autotmp_3+15(SP)
0x0051 00081 (defer.go:10) MOVQ $0, "".~r0+48(SP)
0x005a 00090 (defer.go:10) MOVB $0, ""..autotmp_3+15(SP)
0x005f 00095 (defer.go:10) MOVQ ""..autotmp_5+16(SP), AX
0x0064 00100 (defer.go:10) MOVQ AX, (SP)
0x0068 00104 (defer.go:10) PCDATA $1, $1
0x0068 00104 (defer.go:10) CALL "".f.func1(SB) // *
0x006d 00109 (defer.go:10) MOVQ 32(SP), BP
0x0072 00114 (defer.go:10) ADDQ $40, SP
0x0076 00118 (defer.go:10) RET
0x0077 00119 (defer.go:10) CALL runtime.deferreturn(SB) // *
0x007c 00124 (defer.go:10) MOVQ 32(SP), BP
0x0081 00129 (defer.go:10) ADDQ $40, SP
0x0085 00133 (defer.go:10) RET
"".f.func1 STEXT size=86 args=0x8 locals=0x10
0x0020 00032 (right.go:9) CALL runtime.printlock(SB)
0x0025 00037 (right.go:8) MOVQ "".val+24(SP), AX //*
0x002a 00042 (right.go:8) INCQ AX
0x002d 00045 (right.go:9) MOVQ AX, (SP)
0x0031 00049 (right.go:9) CALL runtime.printint(SB)
0x0036 00054 (right.go:9) CALL runtime.printnl(SB)
0x003b 00059 (right.go:9) NOP
0x0040 00064 (right.go:9) CALL runtime.printunlock(SB)
0x0045 00069 (right.go:10) MOVQ 8(SP), BP
0x004a 00074 (right.go:10) ADDQ $16, SP
0x004e 00078 (right.go:10) RET
不希望的版本:
package main
func f() {
i := 0
defer func() {
println(i) // 1
}()
i++
}
汇编代码如下:
"".f STEXT size=145 args=0x0 locals=0x30
0x0025 00037 (wrong.go:3) MOVB $0, ""..autotmp_2+15(SP)
0x002a 00042 (wrong.go:4) MOVQ $0, "".i+16(SP)
0x0033 00051 (wrong.go:6) LEAQ "".f.func1·f(SB), AX
0x003a 00058 (wrong.go:6) MOVQ AX, ""..autotmp_3+32(SP)
0x003f 00063 (wrong.go:6) LEAQ "".i+16(SP), AX
0x0044 00068 (wrong.go:6) MOVQ AX, ""..autotmp_4+24(SP)
0x0049 00073 (wrong.go:6) MOVB $1, ""..autotmp_2+15(SP)
0x004e 00078 (wrong.go:10) MOVQ "".i+16(SP), AX
0x0053 00083 (wrong.go:10) INCQ AX
0x0056 00086 (wrong.go:10) MOVQ AX, "".i+16(SP)
0x005b 00091 (wrong.go:11) MOVB $0, ""..autotmp_2+15(SP)
0x0060 00096 (wrong.go:11) MOVQ ""..autotmp_4+24(SP), AX
0x0065 00101 (wrong.go:11) MOVQ AX, (SP)
0x0069 00105 (wrong.go:11) PCDATA $1, $1
0x0069 00105 (wrong.go:11) CALL "".f.func1(SB)
0x006e 00110 (wrong.go:11) MOVQ 40(SP), BP
0x0073 00115 (wrong.go:11) ADDQ $48, SP
0x0077 00119 (wrong.go:11) RET
0x0078 00120 (wrong.go:11) CALL runtime.deferreturn(SB)
0x007d 00125 (wrong.go:11) MOVQ 40(SP), BP
0x0082 00130 (wrong.go:11) ADDQ $48, SP
0x0086 00134 (wrong.go:11) RET
"".f.func1 STEXT size=86 args=0x8 locals=0x10
0x0020 00032 (wrong.go:7) CALL runtime.printlock(SB)
0x0025 00037 (wrong.go:7) MOVQ "".&i+24(SP), AX // *
0x002a 00042 (wrong.go:7) MOVQ (AX), AX
0x002d 00045 (wrong.go:7) MOVQ AX, (SP)
0x0031 00049 (wrong.go:7) PCDATA $1, $1
0x0031 00049 (wrong.go:7) CALL runtime.printint(SB)
0x0036 00054 (wrong.go:7) CALL runtime.printnl(SB)
0x003b 00059 (wrong.go:7) NOP
0x0040 00064 (wrong.go:7) CALL runtime.printunlock(SB)
0x0045 00069 (wrong.go:8) MOVQ 8(SP), BP
0x004a 00074 (wrong.go:8) ADDQ $16, SP
0x004e 00078 (wrong.go:8) RET
逃逸分析意思是编译器对代码进行分析,发现某些分配在堆上的对象没有必要转为分配在栈上,或者看起来是分配到栈上的对象需要更长的生命周期,转而分配到堆上。
// go build -gcflags=-m main.go
func foo1() *person {
// 分配到堆上
return &person{Name: "zhangsan"}
}
/*
0x001d 00029 (main.go:9) LEAQ type."".person(SB), AX
0x0024 00036 (main.go:9) MOVQ AX, (SP)
0x0028 00040 (main.go:9) PCDATA $1, $0
0x0028 00040 (main.go:9) CALL runtime.newobject(SB)
0x002d 00045 (main.go:9) MOVQ 8(SP), AX
0x0032 00050 (main.go:9) MOVQ $8, 8(AX)
0x003a 00058 (main.go:9) LEAQ go.string."zhangsan"(SB), CX
0x0041 00065 (main.go:9) MOVQ CX, (AX)
0x0044 00068 (main.go:9) MOVQ AX, "".~r0+32(SP)
0x0049 00073 (main.go:9) MOVQ 16(SP), BP
0x004e 00078 (main.go:9) ADDQ $24, SP
*/
下面的对象是使用 new 函数分配的,但是编译器是在为期分配到栈上,也可使用 go build -gcflags=-m main.go 来查看编译器的分析。
// go build -gcflags=-m main.go
// new(person) does not escape
func foo3() {
// 分配到栈上
p := new(person)
p.Name = "zhangsan"
println(p)
}
/*
0x0020 00032 (main.go:21) CALL runtime.printlock(SB)
0x0025 00037 (main.go:21) LEAQ go.string."zhangsan"(SB), AX
0x002c 00044 (main.go:21) MOVQ AX, (SP)
0x0030 00048 (main.go:21) MOVQ $8, 8(SP)
0x0039 00057 (main.go:21) CALL runtime.printstring(SB)
0x003e 00062 (main.go:21) NOP
0x0040 00064 (main.go:21) CALL runtime.printnl(SB)
0x0045 00069 (main.go:21) CALL runtime.printunlock(SB)
0x004a 00074 (main.go:22) MOVQ 16(SP), BP
0x004f 00079 (main.go:22) ADDQ $24, SP
0x0053 00083 (main.go:22) RET
*/
不过,改一下这个打印函数,new(person) 就会 escapses to heap,修改如下:
// go build -gcflags=-m main.go
// new(person) escapes to heap
func foo3_1() {
// 分配到堆上
p := new(person)
p.Name = "zhangsan"
// 传递的是 []interface{}
fmt.Printf("%v", p)
}
原因是 fmt.Printf 函数传递的不定参数是 []interface,p 通过地址转换过去,不过事情并不总是像看到的这样,下面的函数按道理是分配到堆上:
type point struct {
x, y int
}
func move(p *point) {
p.x = 10
p.y = 10
}
func main() {
// 分配到栈上,注意 move 函数被内敛了
p := new(point)
move(p)
print(p)
}
先使用 go build -gcflags=-m main.go 分析,结果显示:
./main.go:13:6: can inline move
./main.go:34:6: can inline main
./main.go:37:6: inlining call to move
./main.go:13:11: p does not escape
./main.go:36:10: new(point) does not escape
注意 p 和 new(point) 都是 does not escape,为什么呢? 因为 move 函数被 inline 了(可以使用 //go:noinline 取消内敛),main 函数的汇编代码如下:
/*
0x001d 00029 (main.go:15) XORPS X0, X0
0x0020 00032 (main.go:14) MOVUPS X0, ""..autotmp_2+8(SP)
0x0025 00037 (<unknown line number>) NOP
0x0025 00037 (main.go:8) MOVQ $10, ""..autotmp_2+8(SP)
0x002e 00046 (main.go:9) MOVQ $10, ""..autotmp_2+16(SP)
0x0037 00055 (main.go:16) PCDATA $1, $0
0x0037 00055 (main.go:16) CALL runtime.printlock(SB)
0x003c 00060 (main.go:16) LEAQ ""..autotmp_2+8(SP), AX
0x0041 00065 (main.go:16) MOVQ AX, (SP)
0x0045 00069 (main.go:16) CALL runtime.printpointer(SB)
0x004a 00074 (main.go:16) CALL runtime.printunlock(SB)
0x004f 00079 (main.go:17) MOVQ 24(SP), BP
0x0054 00084 (main.go:17) ADDQ $32, SP
0x0058 00088 (main.go:17) RET
*/
汇编代码中调用的 runtime.xxx 函数源代码在哪里呢? 参考 https://github.com/golang/go/tree/master/src/runtime
本章节的代码 https://github.com/developdeveloper/go-demo/tree/master/29-decompile-memory
30-OOP 的 AFIB 模型
从 oop 的角度来看,完整的系统几乎都包含了这四个部分(简称为AIFB):
- 抽象 Abstract: 对要解决的问题建立一定的机制,为类似的问题提供通用的模型。
- 实现 Implemention: 有了抽象的模型,但没有提供实际解决问题的方法,所谓实现就是用来提供具体达到目标的方法。
- 框架 Framework: 有了抽象和实现已经可以解决定义的问题了,但是怎么去使用呢?这就需要提供一定的使用流程来连接。
- 业务 Business: 有了框架已经可以正常去调用这个系统了,把它应用到具体的场景中,这就是一套面向业务的流程,来解决真正的客户的需求。
从一个很微小的例子来理解这4个层次,假设客户的需求是:用手机给张三打电话。
第一层抽象: 很显然核心的要点是打电话,至于打给谁,用什么手机,这些不是关键点,这个系统如果只能给张三打电话,显然会显得很鸡肋,下次你要给李四打电话,你会重新做一个系统吗? 不会,对不对;如果系统做成只能使用评估手机打电话,那下次调用的时候,调用者没有苹果手机,只有华为手机,那怎么办? 这个系统还不能用了,又得重新做一个,对不对? 所以针对这个需求,可以适当的抽象出: 可以用任意能打电话的手机,给 XXX 打电话。定义一个打电话的行为,这就是适当的抽象:
// 抽象 Abstract
type Phone interface {
Call(name string)
}
第二层实现: 有了接口对打电话的行为做出了具体的定义,那么具体由什么手机来打呢? 不同的手机应该有不同的实现。对于苹果手机和华为的手机分别来提供打电话这个行为的方法:
// 实现 Implention
// Apple 苹果手机得这么打
type ApplePhone struct {}
func (phone *ApplePhone) Call(name string) {
fmt.Println("apple call " + name)
}
// Huawei 华为手机这么打
type HuaweiPhone struct {}
func (phone *HuaweiPhone) Call(name string) {
fmt.Println("huawei call " + name)
}
第三层框架: 有了苹果和华为的手机,就能实现打电话这个行为了,但是具体打电话的过程还是没有的,为了让这个行为更易使用,需要一个框架来整合一下,但是框架其实不关心具体打电话的过程内部是怎么实现的,它只完成打电话这个动作:
// 框架 Framework
// phone 参数: 能打电话设备
// names 参数: 要打给谁谁谁
func doCall(phone Phone, names... string) {
for _, name := range names {
phone.Call(name)
}
}
第四层业务: 系统功能都具备了,终于可以使用了,在具体场景中去使用吧,给张三打个电话,可以用苹果手机,也能用华为手机:
// 业务 Business
func main() {
var phone Phone
phone = &ApplePhone{}
doCall(phone, "zhangsan", "lisi")
phone = &HuaweiPhone{}
doCall(phone, "zhangsan", "lisi")
}
如果将来你换了 Oppo 的手机,你只需要提供一个 OppoPhone 的实现层就行了,代码清晰易改动:
// Oppo 手机得这么打
type OppoPhone struct { }
func (phone *OppoPhone) Call(name string) {
fmt.Println("oppo call " + name)
}
这个例子足够小,但是体现了 oop 设计的理念和常用的模型,不管使用什么语言,什么场景,这套基本的方法流程是通用的。
31-接口、继承、多态
接口 interface 规定了具备某种行为能力的对象,为了系统更容易扩展和维护,常常需要面向接口编程,接口是抽象的一种表达形式。比如作为 Animal 动物这个抽象类型,应该有吃饭和睡觉的行为,同时都作为宠物的属性都能和人一起玩耍,没问题吧?
type Animal interface {
eat(food string)
sleep(hours uint)
playAsPet()
}
如果一个对象拥有了接口所定义的行为,那么就说这个对象实现了该接口,也可以安全的转换为对应的接口对象。比如猫和狗都具备了 Animal 的行为,它们就可以被安全的转换为 Animal 这个类型。
// 猫
type Cat struct {}
func (cat *Cat) eat(food string) {...}
func (cat *Cat) sleep(hours uint) {...}
func (cat *Cat) playAsPet() {...}
// 狗
type Dog struct {}
func (dog *Dog) eat(food string) {...}
func (dog *Dog) sleep(hours uint) {...}
func (dog *Dog) playAsPet() {...}
为什么猫和狗不直接使用 Animal 来表达呢? 因为猫和狗虽然具备了一些相同的行为,并同时也具备了很多不同的行为,当你想收拾一只老鼠的时候,肯定是派一只猫去更合适,对吧(有人不这么想)? 当你想留一个看家的时候,肯定是狗要合适些,对吧?
// 猫捉老鼠
func (cat *Cat) catchMouse() {...}
// 狗来看家
func (dog *Dog) defendHouse() {...}
可见接口用来抽象共同的行为,当你寂寞想找个宠物放松一下时,去找 cat 和 dog 都可以满足你,但当你需要捉老鼠或者看家的时候,你就不能随便选一个了。
回到 playAsPet() 上来,很显然和猫玩耍的方式与狗不同,猫可能喜欢陪你在家看书,而狗更合适陪你去户外遛弯,虽然都能陪你打发时间,但是你的体验会不一样,这就是多态! 来看看多态教科书的表达: 多态是同一个行为(playAsPet)具有多个不同表现形式或形态的能力(看书、遛弯);多态就是同一个接口(Animal),使用不同的实例(Cat、Dog)而执行不同操作(catchMouse、defendHouse)。
那么继承又有什么用呢? 拿 Dog 来举例子,狗还有很多种,对吧? 比如警犬,不仅能吃、能睡、陪你玩,还能帮你抓到犯罪嫌疑人,当你的系统要表达一只警犬的时候,你不想把 eat、sleep、playAsPet 重新都写一遍对吧? 如果你想对 playAsPet 方法做一些修改,作为宠物来讲,它也应该同时被修改对吧? 所以最好的方式就是继承 Animal 的行为,定一个能辅助警察工作的类型,而警犬是其中一个特例,比如它可能是德国牧羊犬,有可能是昆明犬,对吧?
// 能帮警察搞事情的动物
type PoliceAnimal interface {
Animal
arrestBadMan()
}
// 牧羊犬
type HuntawayDog struct {
Dog
}
func (huntawayDog *HuntawayDog) arrestBadMan() {...}
你现在想让 HuntawayDog 或者 KunmingDog 陪你散散步,是没有问题,对吧? 所以你现在可以一个能吃、能睡、能陪你玩,还能抓捕坏人的朋友,你可能需要的是 PoliceAnimal,当你真的要执行抓捕任务的时候,不管是 HuntawayDog 还是 KunMingDog,都能完成任务。
func atPeace(animal Animal) {
animal.eat("meat")
animal.sleep(10)
animal.playAsPet()
}
func doTask(animal PoliceAnimal) {
animal.arrestBadMan()
}
func main() {
huntawayDog := &HuntawayDog{}
atPeace(huntawayDog)
doTask(huntawayDog)
}
不同的语言对接口、多态、集成的支持力度不同,但核心思想如此,剩下的只是语法的表达。
S.O.L.I.D:
- SRP Single responsibility Principle 单依职责原则
- OCP Open Closed Principle, 开放关闭原则
- LSP Liskov Substitution Principle 里氏替换原则
- ISP Interface Segregation Principle 接口隔离原则
- DIP Dependency Inversion Principle 依赖倒置原则
- LKP Least Knowledge Principle 迪米特法原则